Introduction
With the development of computational resources, supercomputers become increasingly used for high-fidelity numerical fluid simulations, Machine Learning (ML) or Artificial Intelligence (AI) applications. In order to run these simulations on a supercomputer, users generally request a number of Central Processing Units (CPUs) or Graphical Processing Units (GPUs) for a certain amount of time (= requested time or wall clock time).
However, many users do not really pay attention to the requested time and set them to the maximum allowed. This is sub-optimal in various ways for the supercomputer efficiency and the user experience.
Indeed, jobs that run much less time than the requested time could have benefited from the backfill mechanism on the supercomputers where it is allowed. Basically, when some resources are not used but planed for a job (job1) that is waiting for more resources, if another job (job2) can run on the free nodes without altering the start time of job1, then job2 will start to run on the free nodes. In 2002, Chiang et al. [1] studied the impact of more accurate requested job times on the production of a supercomputer. Results showed that when the requested times were more accurate, the slowdown (time between the submission and the end of the job divided by the time between the start and the end of the job) was decreased by a factor 2 to 6.
Another sub-optimal practice related is to run a job until the end of the requested time without writing an output at the end. Imagine a numerical simulation that requires 12 chained jobs running on 1000 CPUs to reach a simulation time. If for each of these chained jobs, the solution to restart the next simulation was written 30 minutes before the end of the job, that means that \(12 \times 0.5 \times 1000 = 6000\) CPU hours were completely wasted.
Finally, the rise of AI runs on clusters is shifting the pressure. AI users habits are different, with notably node-sharing and interactive jobs. AI and “classical” users will collide in the future. We need solutions to forecast how the communities interact. The first step is an accurate data driven model of users habits.
In our effort in the assessment of users, supercomputers usage habits are collected in the in-house open-source tool Seed.
Seed
Seed is a python software developed at CERFACS. Seed can analyze basic jobs characteristics submitted by the users such as the distribution of the duration of the jobs, the number of CPUs allocated, the number of CPU hours, the inter arrival time of the jobs, the waiting times, the slowdown and the accuracy of users. The accuracy (the actual time of the job divided by the requested time) is of particular interest, since as mentioned earlier, imprecise accuracy are associated with larger waiting times and slowdown.
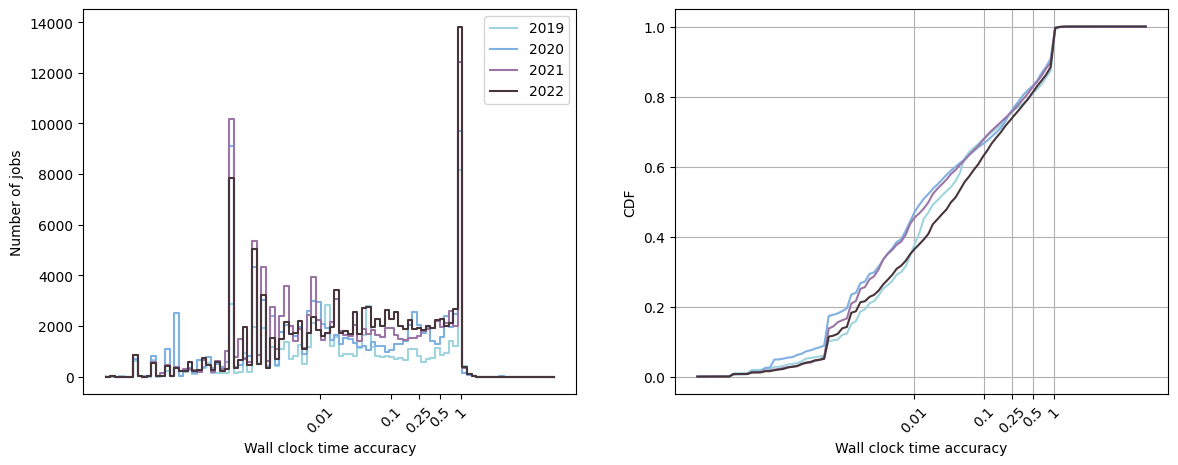 Histograms (left) and Cumulative Distribution Function (right) of the accuracy of the users for various years on a supercomputer.
Histograms (left) and Cumulative Distribution Function (right) of the accuracy of the users for various years on a supercomputer.
Fig. 1 displays the histograms and Cumulative Distribution Function (CDF) for the users accuracy along the years on an in-house supercomputer. You can observe, especially with the CDF, that approximately 80 % of the jobs have an accuracy inferior to 0.5, meaning that the requested time is twice inferior to the actual running time. This is clearly sub-optimal for the resources management system.
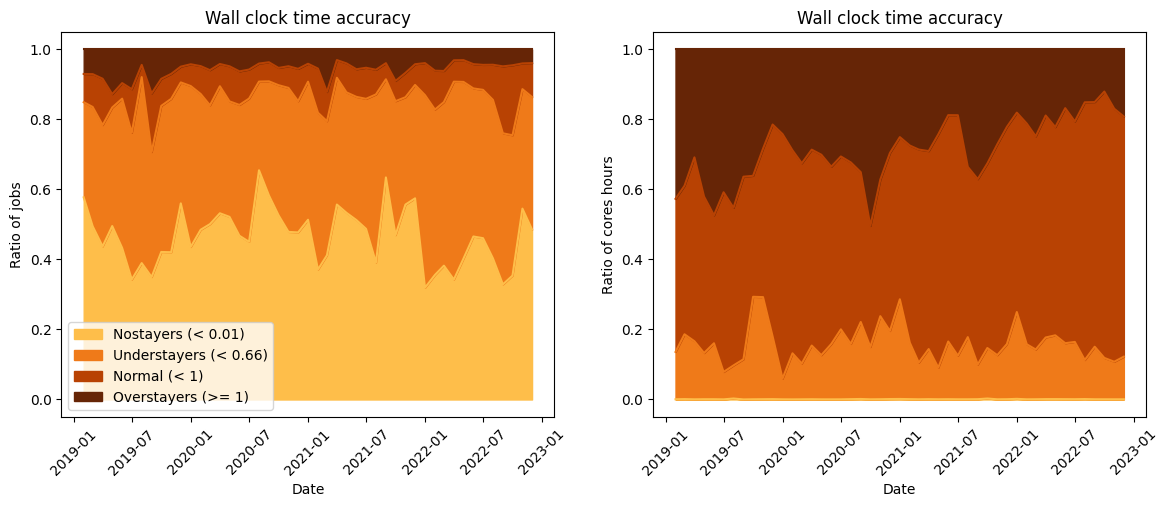 Distribution of various categories of accuracy as a function of the time in terms of number of jobs (left) and CPU hours (right).
Distribution of various categories of accuracy as a function of the time in terms of number of jobs (left) and CPU hours (right).
We can also look at the evolution of users accuracy month by month as in Fig. 2. We classified the users as “no stayers” (the job instantly crashes/finishes despite a large requested time), “understayers” (only 2/3 of the requested time was used for the job), the “normal” ones (between 2/3 of the requested time and strictly inferior to the request time) and the “overstayers” (the ones that stay until the end of the requested time). You can observe that along the years, approximately 40% of the jobs crashed instantly (“no stayers”) and that there are only approximately 10% of the jobs well calibrated (“normal”). However, we note the global progression of the “normal” submissions in terms of CPU hours along the years, which shows that users are paying more and more attention to the requested time.
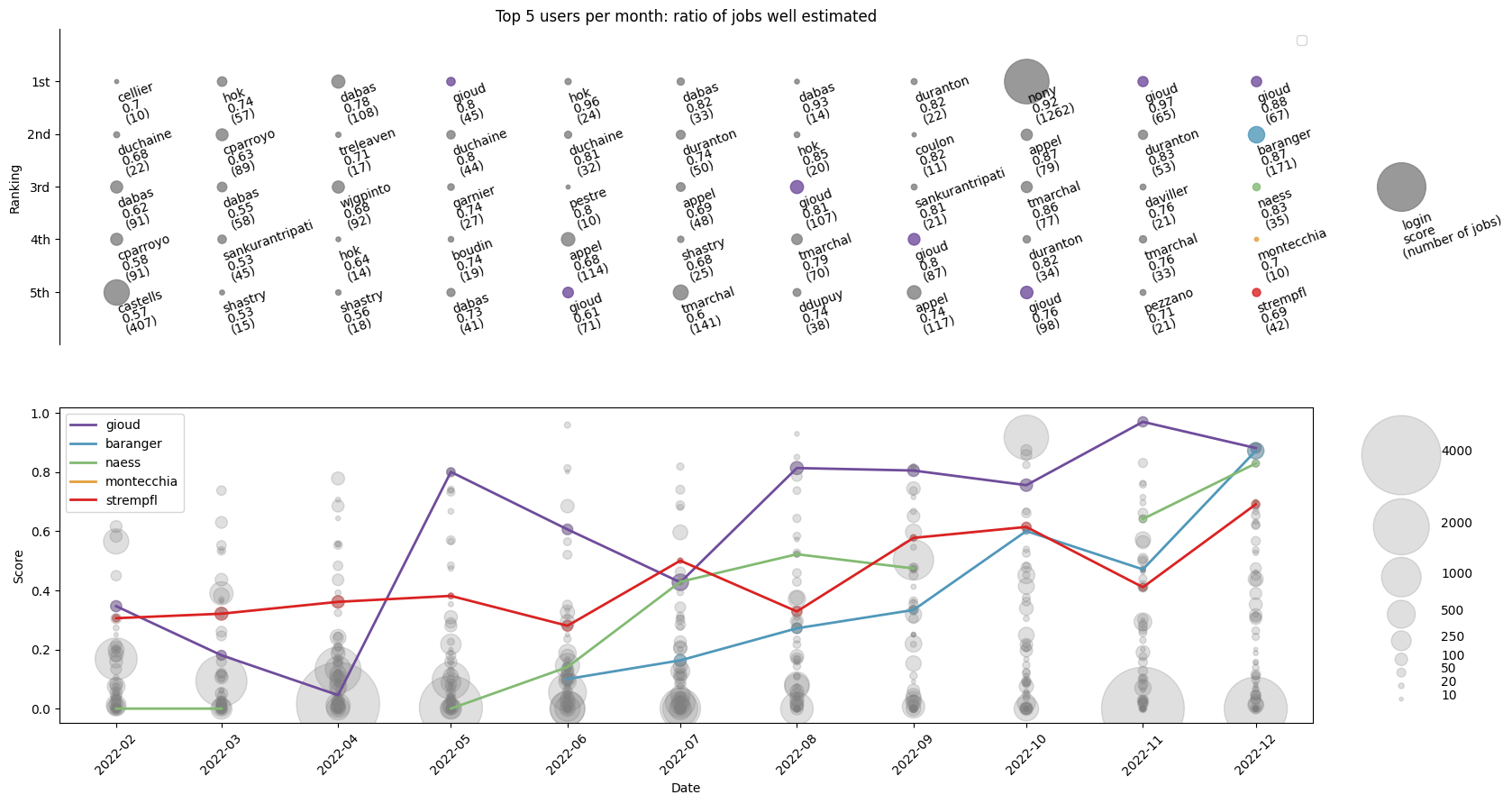 Top 5 of the users with their ratio of jobs with an accurate requested time (top) and evolution of the best 5 users of the last month (bottom).
Top 5 of the users with their ratio of jobs with an accurate requested time (top) and evolution of the best 5 users of the last month (bottom).
In order to encourage the users to be more accurate on the requested time, we developed in Seed, an analysis tool to highlight the people with the best ratio of jobs with an accurate requested time (category “normal”) on the production jobs. This top 5 is displayed in Fig. 3 where the score is computed as the number of jobs with an accurate requested time divided by the total number of jobs run by the users on production queues. With this graph, we aim to both congratulate users who tailored the requested time to their jobs and to follow their progression.
Finally, in order to gather more information about the users jobs and to assess which community was the most subject to poor estimated wall clock time, we encouraged the users to tag their jobs with the software they were using. We were then able to evaluate the number of CPU hours dedicated for each software and perform an analysis similar to Fig. 1 and Fig. 2 to check the differences in jobs submissions between various communities of users.
Conclusions et perspectives
In this paper, we introduced a first step in the modeling of users behaviour to forecast the usage of future supercomputers architectures. We especially highlighted the importance of modeling the requested time and introduced Seed to perform analysis of the users submission patterns and/or improve the behaviour of the users on a supercomputer.
In a long run, we would like to develop advanced workload models based on the users submission patterns. Zakay and Feitelson [2] developed a workload model to preserve the users experience in terms of time of submission. This kind of models could be improved with an users accuracy model to assess the impact of sub-optimal and optimal accuracy on various virtual machines.
Acknowledgement
Funded by the European Union. This work has received funding from the European High Performance Computing Joint Undertaking (JU) and Germany, Italy, Slovenia, Spain, Sweden, and France under grant agreement No 101092621.


Disclaimer
Funded by the European Union. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European High Performance Computing Joint Undertaking ( JU) and Germany, Italy, Slovenia, Spain, Sweden, and France. Neither the European Union nor the granting authority can be held responsible for them.
References
-
S.-H. Chiang, A. Arpaci-Dusseau, and M. K. Vernon, “The impact of more accurate requested runtimes on production job scheduling performance,” in Job Scheduling Strategies for Parallel Processing: 8th International Workshop, JSSPP 2002 Edinburgh, Scotland, UK, July 24, 2002 Revised Papers 8, pp. 103–127, Springer, 2002.
-
N. Zakay and D. G. Feitelson, “Preserving user behavior characteristics in trace-based simulation of parallel job scheduling,” in Proceedings of the 8th ACM International Systems and Storage Conference, pp. 1–1, 2015.