What is CERFACS?

CERFACS, Centre Européen de Recherche et de Formation Avancée en Calcul Scientifique or, in English, the European Centre for Advanced Research and Training in Scientific Computing, is a research centre in Toulouse. It focuses on high performance computing (HPC), in fields like aerodynamics, combustion and propulsion, energy, and climate science.
But what is high-performance computing? It involves using supercomputers that can run thousands of calculations at the same time to solve complex problems. But this requires teams of experts – physicists to create the models, mathematicians to build numerical methods, engineers to assemble and maintain the machines themselves, and computer scientists to get it all running smoothly.
So, to make life easier, various shareholders (Airbus, CNES, EDF, Météo-France, ONERA, Safran, and Total) decided to collaborate. And that’s how the CERFACS was born: a space where all experts in various fields could work collaboratively in high performance computing. On top of its research activities, CERFACS also provides training, with many PhD students coming here to gain experience and work on real-world problems.
And the COOP?
So, what is the COOP’s job in all of this? Their job focuses on the software side of high-performance computing — making academic code run efficiently in the real world. That might include adapting software for use in industry, developing customised AI tools, porting code so it works on different types of supercomputers, and optimising performance so the code runs as fast and efficiently as possible. They also build tools that help researchers understand complex programs more easily — because in HPC, the code can get really complicated, really fast.
Making Sense of Software
Software used in HPC today is extremely long. For example, the AVBP (a combustion simulation software developed at CERFACS) would take 10000 hours to read through just once! And that wouldn’t guarantee having grasped it all…
To help make sense of such codes, the COOP team builds visualisations such as callgraphs. A callgraph is like a map of the program – it shows how all the different parts are interlinked. Often, in software, a function will call on another function, which itself may call on another one and so on… It’s very easy to get lost, like reading a book where each sentence jumps to a different page which then jumps to a different page and so forth. And to make matters worse, the book itself is huge – and probably would need to be contained in multiple thick volumes… So instead, these ‘maps’ can be used to make sense of the whole thing. And it means that someone working on the software can focus on a specific part without needing to read the whole program. They can just look at the map to be aware of the structure and the parts they are affecting! Callgraphs allows researchers to be able to develop the code without having to spend ages labouring through lines and lines of programming to understand it.
Older callgraphs were quite simple and static, giving you the structure and that’s it. Now, the whole thing is much more interactive – click on a function and it will give you more information. You can even switch colour schemes depending on what you want to analyse. For instance, by colouring parts based on how many lines they contain, to quickly spot the most complex areas. It’s interactive, fun and with bright colours! What more could you want?
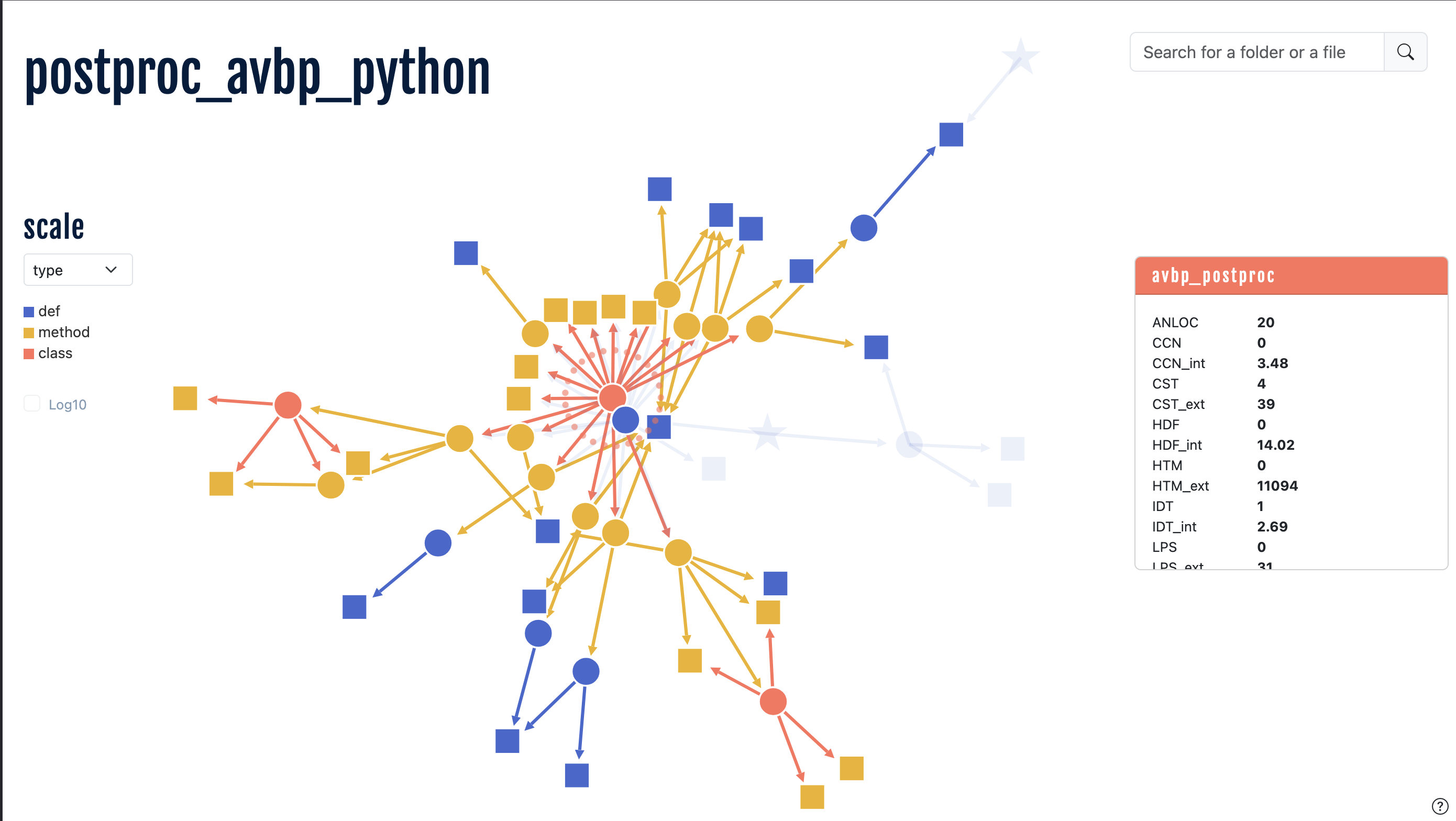 The callgraph of a program created by the COOP team. Each node is a part of the program. Blue nodes are simple independent parts, while Yellow nodes are sharing information through the Orange ones.
The callgraph of a program created by the COOP team. Each node is a part of the program. Blue nodes are simple independent parts, while Yellow nodes are sharing information through the Orange ones.
Porting
Supercomputers are different everywhere, with different structures and components. So software has to be adapted to run correctly and efficiently on a new machine. This is called porting.
On recent challenge is the rise of GPUs (Graphics Processing Unit). They were created specifically for graphics and are very good at doing the same type of calculation many times in parallel. This means that they’re excellent at doing one very specific task very quickly. However, they’re not as versatile as CPUs (Central Processing Unit), use different kinds of code, and need CPUs to move data around.
However, GPUs are used a lot in AI, which means that supercomputers are increasingly built with more and more GPUs. There’s a real sense in which new supercomputers are designed with AI (and hence the general public) in mind, rather than focusing on the needs of high-performance computing. And so, computer scientists in the COOP team need to work around this and find ways of porting software to machines that are increasingly more difficult to work with.
Optimising Performance
Another part of the COOP’s job is trying to optimise performance, or making software run faster and more efficiently.
First, they find the theoretical optimal performance of the software. Then, they compare that to the actual performance. If there is a difference, then they start looking for what’s bringing the performance down.
Maybe a specific calculation is being repeated uselessly; maybe something could be run on a GPU to go faster. They may also work with the supercomputers’ engineers, who will know the tricks for best optimising on their specific machine. It seems like quite a detective work, looking at all the nitty-gritty bits to work around the problems and find outside the box solutions!
Ultimately though, HPC relies on doing many calculations all at once. But there’s a limit to how much you can speed things up. Some operations just cannot be run in parallel. For example, one might depend on the result of another one, so you have to wait until the first one is finished to move to the next one. As a result, there is an inherent limit in the performance of a supercomputer, which is shown by Amdahl’s law. It basically says that, even if adding an infinite amount of resources, the speed will depend in the end on how much of the operations can be run parallel. Which makes sense: when making a stew, you might put in as many vegetables in the pot as you want to go faster, but you can’t get rid of the time to chop them all!
Lemmings
Another tool that the COOP work on is called Lemmings. Supercomputers have a limit on how long a job can run for. So, for example, after 12 hours, the job will stop. But maybe the simulation needs more time, so you’d have to manually restart it, having updated the necessary parameters. But instead, Lemmings can automatically resubmit the job once the time limit has been reached. In academic research, precision is often the priority — researchers may run detailed simulations, tweaking tiny parameters to understand how the system behaves under different conditions. But in industry, speed and efficiency matter more. The goal is usually to run many simulations quickly and check that the results are consistent, rather than spending lots of time refining each one. That’s why tools like Lemmings are so valuable: they help automate the process and keep things running smoothly, without needing someone to restart the job every time.
Industry
The COOP team also develops tools that make it easier for companies like SAFRAN to use advanced simulations, such as for designing and testing combustion chambers in aircraft engines. One key part of this is building user interfaces that allow engineers to run complex simulations more easily.
The simulations do still require a huge amount of input data. For example, combustion chambers have thousands of tiny holes across their surfaces, carefully placed to control temperature. The location, size, and number of these holes all needs to be entered into the simulation. The COOP team creates interfaces that make this possible, allowing engineers to input data efficiently and explore different design scenarios.
Once that’s done, simulations can help test and improve real engine designs. For instance, SAFRAN might build a prototype and coat it with a special paint that reveals how hot different parts of the combustion chamber get during operation. If some areas are getting too hot, which means they’ll wear out after a certain time of flight, they’ll need to make changes. One fix might be to add more cooling holes in that region. But adding holes in one place often means reducing them somewhere else. This is where simulations become crucial: they let engineers test different hole patterns and see the impact without having to build a new prototype each time.
There’s also the question of manufacturing precision. In real life, holes might not be drilled perfectly and might be slightly off in size or position. Engineers need to know whether those tiny differences will affect performance. To answer that, they rely on high-fidelity simulations and the tools the COOP team builds make those simulations possible.

Simulation of a Siemens Turbine
Custom AI
The COOP team is also working on creating customised AI tools, for sensitive environments as well as high-performance computing.
Imagine a confidential meetings which needs to be summarised. The transcript can’t be put on a public platform like ChatGPT or Gemini. Instead, an internal tool has to be used to summarise what was said – which is what the team has been working on.
As well, they’re starting to work on an AI assistant that could help with high-performance computing. It could explain a code in plain English, refactor it (rewriting it without changing how it works), or translate between programming languages. In the long term, the tools might become more sophisticated, helping with compilation, and performance.
All of this has the potential to greatly help with HPC – for example, AI could help work out which parts of a code can be run in parallel and hence which is suited to run on a GPU, an important part of making sure HPC is effective. It’s a fun and exciting project – getting to create new tools to help in the future.
Conclusion
Overall, the COOP team works on a wide range of projects in scientific software, ranging from supporting industry with simulation tools to acting like code detectives by solving problems in complex codes. Their work blends problem-solving, creativity, and collaboration as they develop cutting-edge solutions in high-performance computing.