AI Copilot Code Quality 2025; Look Back at 12 Months of Data: 4x more code cloning, “copy/paste” exceeds “moved” code for first time in history. (GitClear. 2025. The Impact of AI on Code Quality and Technical Debt).
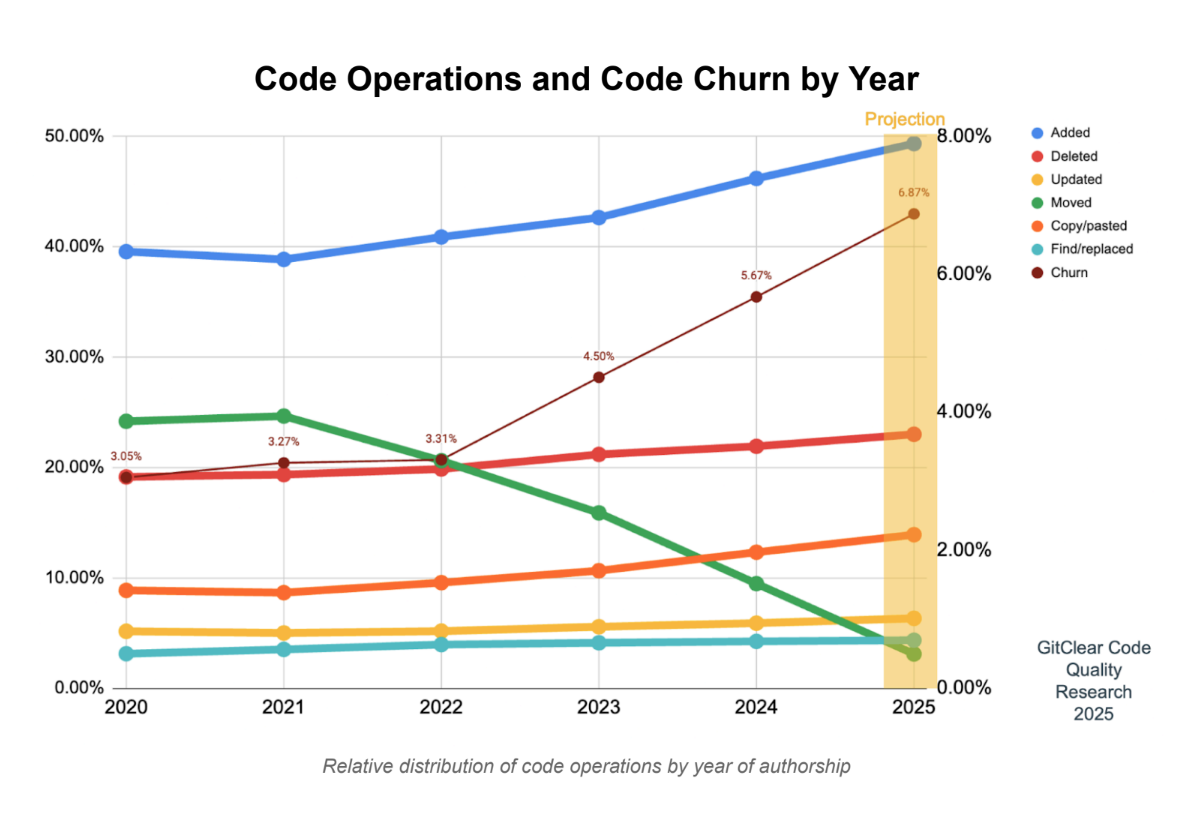 GitClear team examined 5 years worth of data (2020-2024), using (…) 211 million changed lines from repos owned by Google, Microsoft, Meta, and enterprise C-Corps. The focus was to understand how AI Assistants influence the type of code being written. They observe a spike in the prevalence of duplicate code blocks, along with increases in short-term churn code, and the continued decline of moved lines (code reuse).
GitClear team examined 5 years worth of data (2020-2024), using (…) 211 million changed lines from repos owned by Google, Microsoft, Meta, and enterprise C-Corps. The focus was to understand how AI Assistants influence the type of code being written. They observe a spike in the prevalence of duplicate code blocks, along with increases in short-term churn code, and the continued decline of moved lines (code reuse).
A Surge in -duplicated- Code Production
The widespread adoption of AI coding tools has drastically increased code production rates. According to GitHub’s 2025 developer survey, 92% of U.S. developers now employ AI assistants in their workflow. Furthermore, the SWE-bench benchmark indicates an improvement in AI problem-solving success from 4.4% in 2023 to 69.1% in 2025 (Financial Times, 2025).
While these figures demonstrate enhanced productivity, they simultaneously reveal systemic risks: - GitClear’s 2025 report shows an eightfold increase in duplicated code blocks, a clear indicator of declining code maintainability (LeadDev, 2025). - Decreased code reuse and fragmented architecture are becoming common in large-scale repositories.
Thus, although AI coding tools augment developer capabilities, they also exacerbate technical debt and complicate the management of ever-expanding codebases. To the authors knowledge, there is no solid argument allowing to claim the field of scientific computing less exposed to this major trend. On the contrary, AI-based HPC application grew at an unexpected rate and is a major player in the sector now.
The Emerging Imperative Codebase Appraisal
Traditional code review methods—based on manual peer inspection—struggle to cope with the sheer velocity and volume of AI-generated code. This mismatch necessitates the development and deployment of automated codebase appraisal frameworks capable of real-time analysis and quality assurance.
- Emerging tools integrate technical debt detection, automated refactoring suggestions, and priority risk mapping to assist developers at scale.
Emerging Practices for Technical Debt Management and Codebase Appraisal
As the volume of software codebases increases, organizations are exploring a range of techniques to manage technical debt effectively. Both traditional and AI-augmented approaches are now being employed, often in combination, to ensure sustainable code quality.
Traditional Technical Debt Evaluation
Historically, technical debt has been identified through: - Manual code reviews, where experienced developers inspect code for maintainability issues, code smells, and architectural inconsistencies. - Static code analysis tools, such as SonarQube and PMD, which automatically detect predefined patterns associated with poor code quality. - Code ownership models, where domain experts monitor sections of the codebase they maintain.
While these traditional methods offer reliability and human judgment, they are often time-consuming and may not scale well when code is produced at accelerated rates, such as in AI-assisted development environments.
Hybrid Code Review Models
To address scaling challenges without abandoning human oversight, many teams are adopting hybrid code review models. In these models: - Automated tools (e.g., linters, static analyzers) perform first-pass reviews for straightforward issues. - Human reviewers focus on higher-order concerns such as architecture, readability, intent, and potential long-term debt.
Hybrid reviews aim to combine the speed of automation with the depth of human expertise. Research from Microsoft Research (2025) on Proactive Technical Debt Management emphasizes that hybrid systems can improve review efficiency without significant loss of quality.
AI-Augmented Technical Debt Management
Emerging AI-driven tools are enhancing technical debt management by introducing capabilities such as: - Pattern-based debt detection using machine learning models trained on large codebases. - Automated refactoring suggestions, as seen in platforms like Refact.ai and OpenRewrite, which propose semantic-preserving code improvements. - Priority risk mapping, with tools like Stepsize, which leverage historical churn, coupling, and defect data to highlight sections of the codebase most susceptible to future issues.
Recent studies, such as Sun et al. (2025), explore the use of Large Language Models (LLMs) for Self-Admitted Technical Debt (SATD) repayment, proposing new metrics like BLEU-diff and LEMOD to better assess the quality of automated debt fixes (Sun et al., 2025).
A Rationale for Language-Independent Codemetrics KPIs: A Multi-Pole Approach
As codebases grow rapidly, especially under the influence of AI-assisted code generation, traditional language-specific quality metrics are becoming insufficient. There is an emerging need for language-independent codemetrics Key Performance Indicators (KPIs) that can objectively assess project health across three interacting domains: Software, Hardware, and the acting community that we will refer to HumanWare. This multi-pole perspective provides a more holistic view necessary for both human reviewers and AI-based quality assurance tools to operate effectively and in alignment.
Diversity of Codebases
Modern systems are increasingly polyglot: - Web applications frequently mix JavaScript, Python, Rust, and SQL. - Microservices architectures often use different languages per service depending on optimization needs.
Language-specific metrics (e.g., cyclomatic complexity for Java, type coverage for TypeScript) induce biases when dealing wilt multiple-language projects. Indeed, each metric should provide equivalent results when applied to the same algorithm written between two languages. This immediately collides with best practices specific to languages and communities, particularly in scientific computing. For example large operations can be implemented at the array level or by expliciting the loops along the dimensions.
Thus, reliable KPIs must either carefully take into account metric homogeneity, or focus on more abstract properties such as: - Module dependency graphs - Rate of code churn - Size and coupling at the system level - Technical debt ratios over time These metrics must be agnostic to syntax and grammar and instead assess structural and evolutionary aspects of codebases.
Software-Hardware-HumanWare Interaction
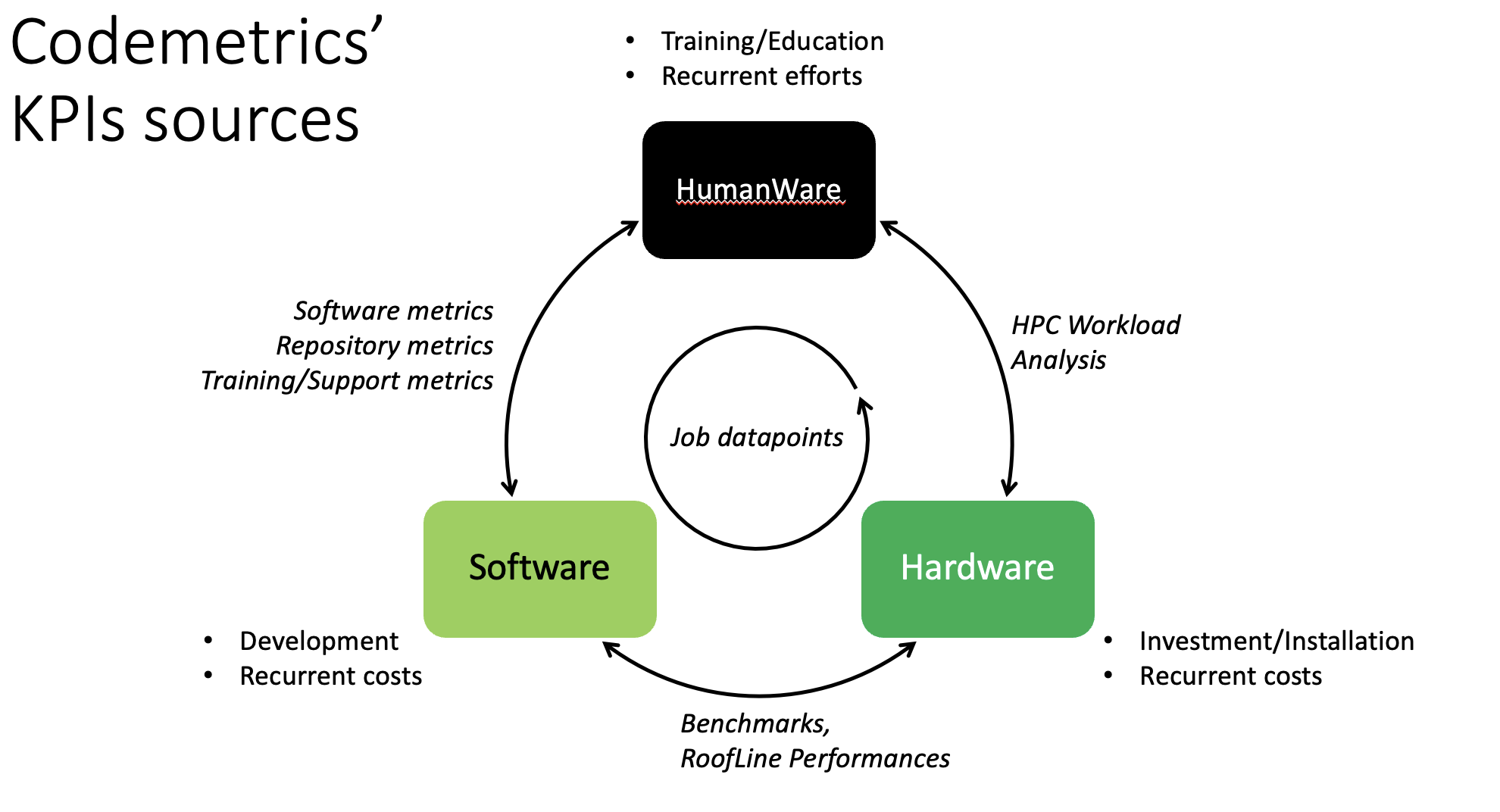 The three poles Hardware, Software and all the human-centric complement in HumanWare. Only the interactions are practically observable
The three poles Hardware, Software and all the human-centric complement in HumanWare. Only the interactions are practically observable
To capture the full reality of modern development, codemetrics must integrate three poles:
Software, Hardware and “HumanWare”
HumanWare refers to the ensemble of human-centric factors — encompassing individuals, teams, organizational practices, and cognitive processes — that interact with both software and hardware to shape the development, maintenance, and usage of scientific computing systems.
In complement to: - Software (the programs, algorithms, and data pipelines) and - Hardware (the physical infrastructure such as HPC clusters, GPUs, and storage systems),
HumanWare includes: - Developer Expertise and Cognitive Load: The capacity of researchers, software engineers, and domain scientists to understand, adapt, and innovate within scientific software environments. - Collaboration Practices: Methods of communication, version control workflows, and interdisciplinary team dynamics critical to the evolution of large-scale computational projects. - Training and Knowledge Transfer: Onboarding processes, documentation quality, reproducibility practices, and institutional memory that sustain the long-term viability of scientific codebases. - Project Management and Governance: Decision-making structures, funding constraints, and prioritization strategies that influence the allocation of human and technical resources.
In scientific computing, where systems are often custom-built, rapidly evolving, and complex, HumanWare is crucial for: - Sustaining code quality over multi-decade project lifespans. - Ensuring reproducibility and verifiability of scientific results. - Enabling the efficient scaling of computational methods to novel hardware architectures. - Preserving critical domain knowledge beyond the tenure of individual contributors. - Developer productivity indicators (e.g., review turnaround times, contribution spread) - Burnout risk factors (e.g., unbalanced task distribution, high-pressure release cycles) - Management-level signals (e.g., velocity vs. quality tradeoffs)
Why focusing on Pole interactions
Observing each pole independently invariably yield lacking conclusions : for example assessing a software performance without considering the hardware, or the code quality without considering the community skills.
On the other hand, Interlinking these poles would allow detection of situations where: - Poor code quality increases build resource demands. - Hardware limitations force hasty architectural decisions by developers. - Excessive technical debt correlates with developer attrition or team instability.
We suggest here various KPIs observable through the interactions of each poles.
Software - Hardware
Here are some KPIs specific to the pair Software - Hardware - Performance Benchmark on execution, strong scalability on a fixed test case - Performance efficiency on executionwith respect to roofline model performances - Compilation speed - Error resilience tests
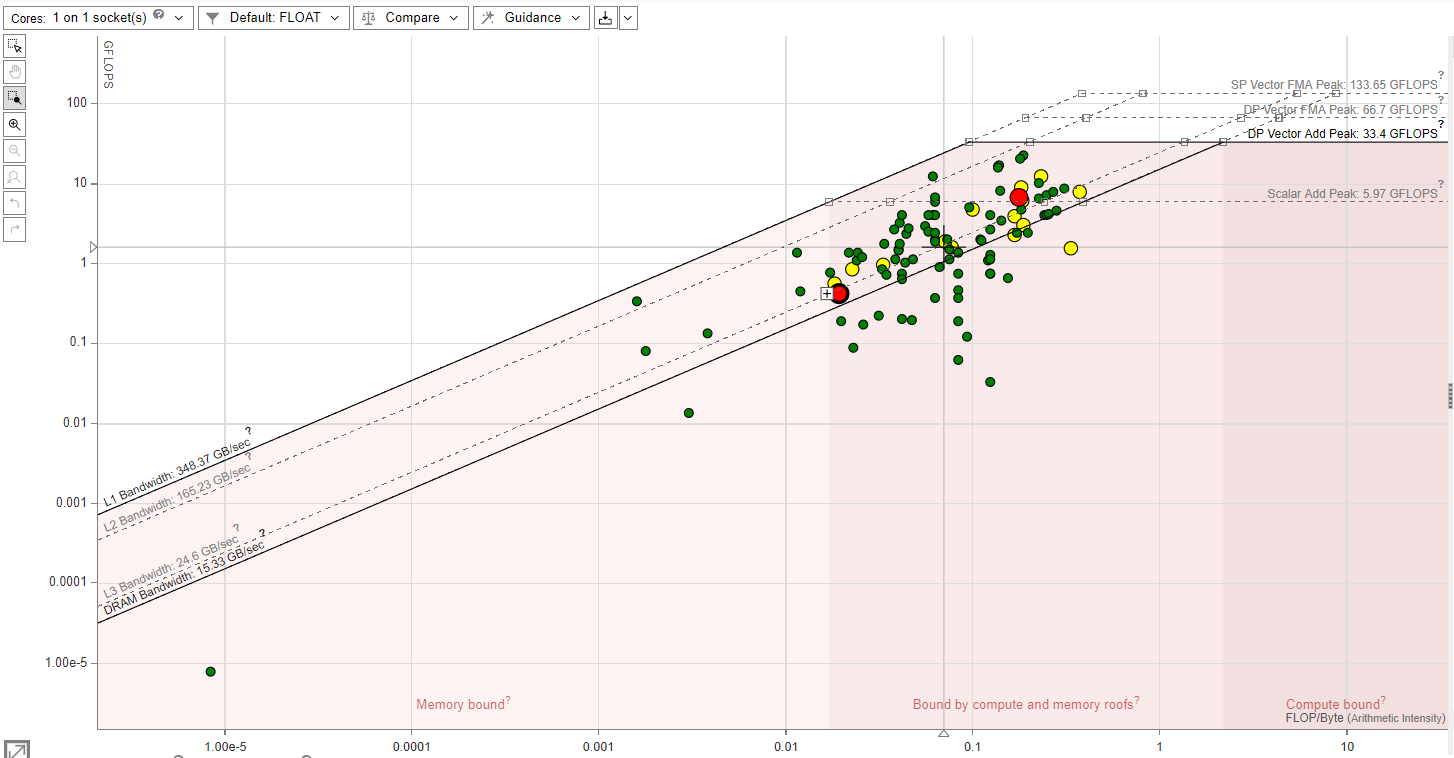 Roofline model graph of a medium sized supercomputer taken form Intel Advisor analysis and a code execution. Here x-axis is arithmetic intensity (FLOP/Byte), y-axis is computational speed (FLOPs). Points are the computational kernels from the execution on an HPC computational fluid dynamics solver. Higher is better porting of a version. Different approaches like going to highr order pushes points to the right.
Roofline model graph of a medium sized supercomputer taken form Intel Advisor analysis and a code execution. Here x-axis is arithmetic intensity (FLOP/Byte), y-axis is computational speed (FLOPs). Points are the computational kernels from the execution on an HPC computational fluid dynamics solver. Higher is better porting of a version. Different approaches like going to highr order pushes points to the right.
Humanware - Software
Here are some KPIs specific to the pair Humanware - Software
- Static code analysis, giving insight on developer creation through a single version of the software
- Repository activity analysis, focusing on developer impact on project activity across time
- Hybrid KPIs such as “commit rates” and “code complexity”, or “hot spots”, highlighting potential recurrent problems
- Support monitoring, exploring the kind of errors reported and how developer answers.
Example with marauder’s map:
- User tolerance to complexity : CCN vs LOCs (Almost)
- Code leveling : complexity CCN vs Argument simplicity
Here is an example of insight provided by Excellerat P2 funded open-source tool Anubisgit :
 Overview of contributors activity to the Git repository of an HPC computational fluid dynamics solver.
Horizontal lines are different branches activity by month. The logarithmic colorscale shows no activity (lightyellow) to high activity (redbrown). This highlights the traffic contrasts between several selected branches - traffic for all remaining branches is cumulated in “Other”.
Overview of contributors activity to the Git repository of an HPC computational fluid dynamics solver.
Horizontal lines are different branches activity by month. The logarithmic colorscale shows no activity (lightyellow) to high activity (redbrown). This highlights the traffic contrasts between several selected branches - traffic for all remaining branches is cumulated in “Other”.
Humanware - Hardware
Here are some KPIs specific to the pair Humanware - Hardware
- Job accounting on a cluster : waiting time, fraction of crashed jobs, fraction of timouts
- Job submission trends : popular submission habits, awareness of scheduling best-practices available (backfill)
Here is an example of insight provided by Excellerat P2 funded open-source tool Seed :
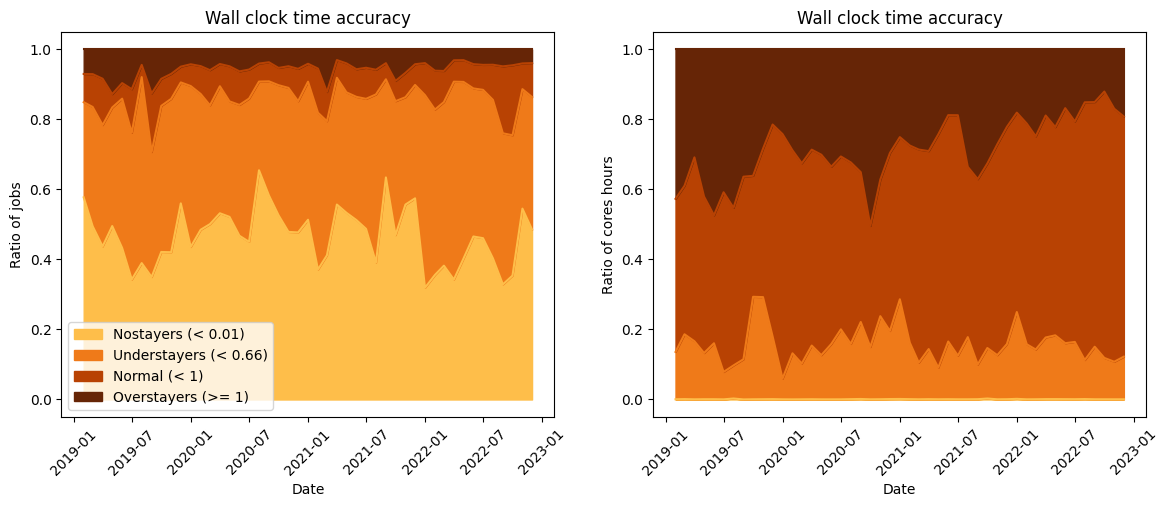 A glimpse at the users habits on a medium size supercomputer. Accuracy being the time run divided by the time requested, this figure shows the monthly evolution of jobs distribution by accuracy. Left is the distribution w.r. to jobs - Half of jobs are stopped before 1% or requested duration/. Right is the distribution w.r. to elapsed CPU hours - circa 30% are done within TimeOut jobs , i.e. no time to save last computation time.
A glimpse at the users habits on a medium size supercomputer. Accuracy being the time run divided by the time requested, this figure shows the monthly evolution of jobs distribution by accuracy. Left is the distribution w.r. to jobs - Half of jobs are stopped before 1% or requested duration/. Right is the distribution w.r. to elapsed CPU hours - circa 30% are done within TimeOut jobs , i.e. no time to save last computation time.
Humanware - Hardware - Software
Here are some KPIs specific to the trio Humanware - Software- Hardware, that we could resume as “Job data points”, because the trio is observable only “job-wise”.
- Metadata on software inputs (models , numerics, computing mesh properties)
- Metadata on software outputs (Performance, timers, error codes, compilation options)
- Snapshot of machine state during job (Hardware material, Memory used, modules loaded)
- Accounting associated to this job (partition, resources requested)
Benefits for Human Overviewers and AI Tool Alignment
Enhanced Human Oversight
Language-independent, tri-polar KPIs provide:
- Simplified dashboards for project leads and architects, regardless of stack complexity.
- Early warnings of systemic issues through cross-domain anomalies (e.g., sudden spike in hardware resource usage linked to specific teams or code modules).
- Better prioritization for refactoring, training, and process improvement initiatives.
Human reviewers are thereby empowered to focus on strategic interventions rather than being overwhelmed by language-specific technicalities.
Improved AI Alignment
AI-based tools benefit from uniform, structured KPIs because: - Metrics feed into training datasets that are consistent across languages and frameworks. - Reinforcement learning loops (e.g., LLM fine-tuning) can target global quality objectives rather than superficial syntactic norms. - Anomaly detection models can operate on language-agnostic feature vectors, improving predictive accuracy across diverse projects.
This fosters better AI-human collaboration in tasks such as: - Prioritizing technical debt repayment - Recommending meaningful refactorings - Alerting project management to cross-domain risks
Conclusion
The transition toward language-independent, multi-pole codemetrics KPIs is not merely a theoretical refinement; it is a practical necessity. As software development becomes more heterogeneous and AI becomes a core participant in the engineering loop, only a holistic measurement framework can ensure maintainability, scalability, and human well-being across projects. Future codemetric systems must therefore move beyond code alone, integrating software structure, hardware performance, and human factors into a unified view.
Feel free to try or fork our Open-Source tools on this topic:
- Marauder’s Map, code mapping, on Gitlab.com or on PiPY.
- Anubis, Git repository analysis over time, on Gitlab.com or on PiPy.
- Seed, HPC workload analysis, on Gitlab.com.
Acknowledgements
This work is part of center of excellence EXCELLERAT Phase 2, funded by the European Union. This work has received funding from the European High Performance Computing Joint Undertaking (JU) and Germany, Italy, Slovenia, Spain, Sweden, and France under grant agreement No 101092621.

