1. The Problem with Compiler Errors: experts cannot get rid of support requests
Compiler errors are brutal. They break your flow, demand precise knowledge of syntax and semantics, and often hide the issue behind layers of jargon. In my case, I can read python traceback or simple Fortran / C++ compilations errors just fine. However, when I am facing a C++ template challenge, I am stuck.
I’ve been experimenting with a tool that turns this process upside down. Instead of leaving you alone with raw error messages, it brings an LLM into the loop. The workflow is simple: feed the tool your code, let it attempt compilation, and if it fails, the model steps in. It explains the error in plain language, proposes a fix, and—if you approve—applies the change it tries compiling again. If the correction doesn’t fit, you can decline and stop the process. You get ,beyond the compiler error, a concept expressed in natural language readable by anyone. It suggests improvements, and handles the trial-and-error cycle for you. It’s not about replacing expertise, but about accelerating the feedback loop and making the compiler a little less of an adversary and more of a teammate.
Compilers are designed for precision, not pedagogy. Their error messages often reflect the internal logic of parsing and type-checking rather than the way humans think about code. As a result, developers get output that’s technically correct but practically unreadable — pointing to syntax trees, tokens, or memory layouts instead of describing the actual mistake in plain terms.
When an error appears, the reaction is trial and error. Developers scan the output, try to guess what’s wrong, and if that fails, copy–paste the error message into a search engine or Stack Overflow. This disrupts the coding flow, breaks concentration, and can lead to hours spent between docs, forums, and code. The issue is that compiler messages don’t bridge the gap between “what went wrong” and “what you should do next.” They diagnose symptoms but rarely prescribe solutions. Beginners find this intimidating, while even experienced developers waste time deciphering messages instead of fixing the underlying issue. This gap makes compilers feel like gatekeepers rather than collaborators.
2. The Idea: Adding an LLM to the Loop
The frustration with compiler errors comes from their one-way nature: the compiler complains, you decipher. What if instead, the compiler could explain what it meant and suggest a fix? That’s where an LLM fits in.
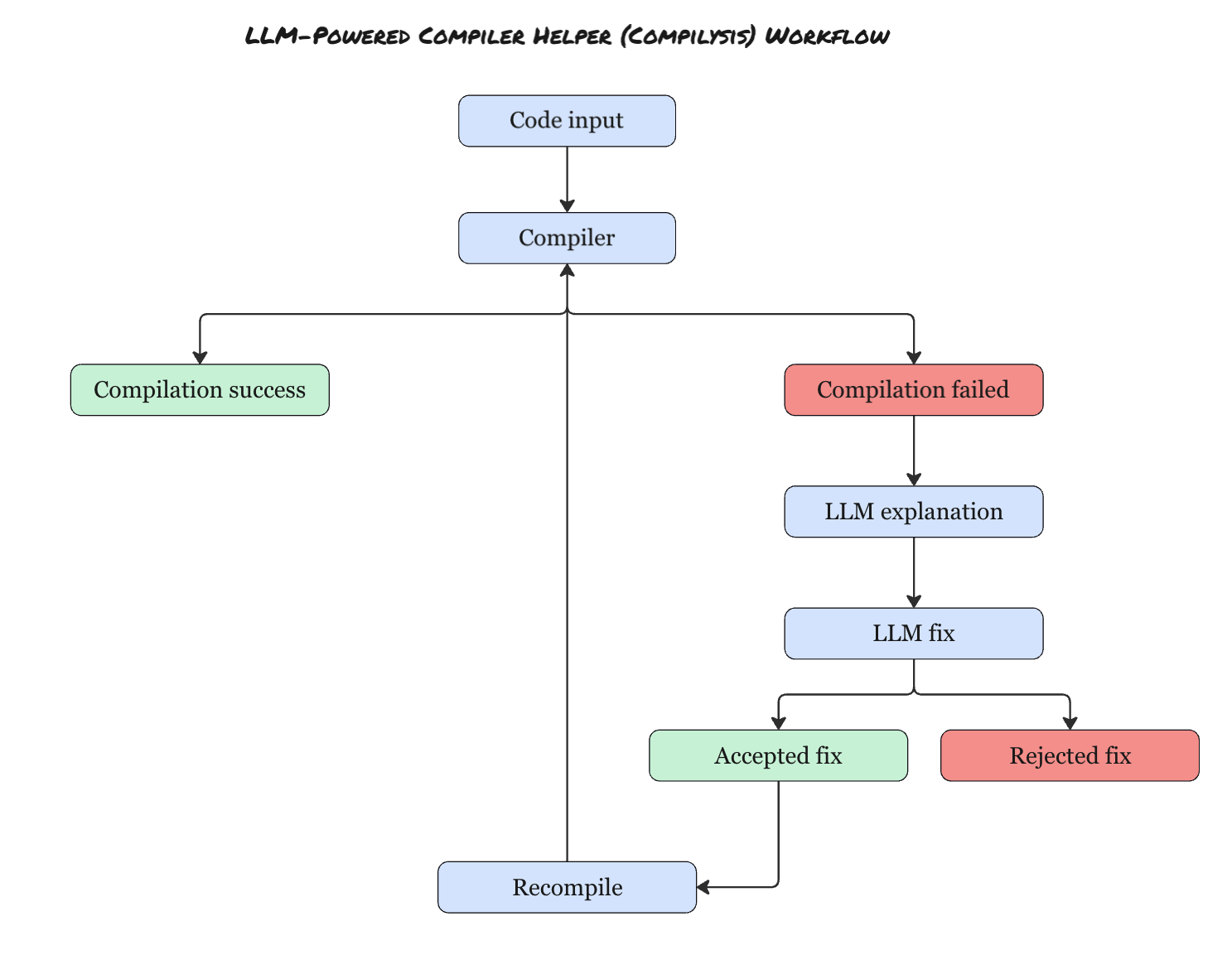 Figure 1: Workflow diagram showing how the LLM-helper Compilysis operates
Figure 1: Workflow diagram showing how the LLM-helper Compilysis operates
The workflow is designed as a loop that layers AI reasoning on top of traditional compilation:
-
Input the code → the tool attempts to compile it.
-
If compilation succeeds → output the result, job done.
-
If compilation fails → the compiler’s raw error message is passed to an LLM.
-
LLM explains the error → in plain, human-readable language, pointing out why it failed.
-
LLM proposes a fix → it generates a corrected version of the code or a minimal change to try.
-
User reviews the suggestion → if accepted, the tool recompiles with the fix; if rejected, the process ends.
-
Loop continues until compilation succeeds or the user decides to stop.
What makes this approach powerful is its interactive, iterative nature. The LLM isn’t replacing the compiler — it’s translating its opaque language into something actionable, then assisting with the trial-and-error cycle. The user stays in control, but the heavy lifting of interpreting and retrying is automated.
3. Designing the Prompt
At the heart of this tool is the prompt — the instructions that tell the LLM how to behave when it receives a compiler error. A poorly designed prompt can lead to verbose explanations, irrelevant guesses, or even “hallucinated” fixes that don’t compile. Getting the prompt right is what makes the system feel like an assistant rather than a noisy chatbot.
In order to be effective, the prompt verify a few quality. First of all, the LLM should explain the compile error in plain language without drowning the user in technical jargon. It should propose a minimal and concrete fix rather than an entire rewritten program. Response should be also predictable, ideally split into two parts, explanation and suggested fix. Moreover, we don’t want any invention on errors or over-correct and only focus on the current failure. Hence, the prompt structure used looks like this :
You are an expert Python developer specialized in building AI-driven tools. You are using LangChain with Ollama and the model qwen2.5:14b.
Your task is to build a Python tool that:
- Accepts Fortran source code as input.
- Attempts to compile the code using gfortran.
Behavior:
- If compilation succeeds:
- Report success.
- If compilation fails:
- Capture the compilation error.
- Generate a response with two parts:
(a) A clear and concise explanation of the error.
(b) A proposed corrected version of the Fortran code.
- Ask the user whether to apply the suggested fix (yes/no).
- If yes: Replace the code with the suggestion and attempt compilation again.
- If no: Stop the process.
- If recompilation after “yes” still fails:
- Loop back to step 2 with the new error and propose a different fix.
Requirements:
- All prompts and outputs must be in English.
- Use loguru for logging to track every step of the process, including compilation attempts, errors, suggestions, user responses, and loop iterations.
4. Building the Tool
The architecture of the helper is intentionally lightweight. It acts as a wrapper around the compiler with an LLM bolted on for interpretation. First, the tool runs a standard compiler command (gfortran here) and captures the output. Depending on the outcome, if it compiles then there is nothing to do, otherwise the raw error message is collected and gathered with the inputed code. Both are sent to the LLM in a structured prompt to get an explanation in natural language, readable by anyone.
Once the explanation and the suggested fix is displayed, you can either accept or decline it. If accepted, the tool we start again the loop.
Here the first prompt is used to get a clear explanation of the error message.
You are an expert Fortran programmer. Analyze the following compilation error and provide a simple, concise explanation.{context}
FORTRAN CODE:
{code}
COMPILATION ERROR (Attempt #{attempt}):
{error}
Please provide a clear and concise explanation of what is causing this compilation error. Focus on:
1. What the error means in simple terms
2. Which part of the code is problematic
3. Why this error occurs
4. If this is a repeated attempt, explain why previous fixes might have failed
Keep your explanation brief and focused.
This second prompt is used to get a fix suggestion.
You are an expert Fortran programmer. Fix the following Fortran code based on the compilation error.{context}
CURRENT FORTRAN CODE:
{code}
CURRENT COMPILATION ERROR:
{error}
Provide ONLY the corrected Fortran code in plain text format.
DO NOT use markdown code blocks (```fortran or ``` tags).
DO NOT include explanations or comments.
Output should start directly with "program" or "subroutine" or whatever the first line of code should be.
Example of correct output format:
program example
implicit none
integer :: i
i = 5
end program example
CORRECTED CODE:
This design doesn’t replace the compiler or change how it works. Instead, it layers AI on top, turning the error output into a dialogue. I also wanted to avoid too much latency between compile attempts. Use a small model in order keep token usage efficient with compact prompts, this is the bottleneck of every tool you might build. The end result is a command-line utility that feels natural: instead of staring at error logs, you’re having a back-and-forth conversation with your “compiler sidekick.”
5. Example in Action
Consider this simple case in Fortran:
program hello
print *, "Hello, world!"
end progrm hello
A human eye spots the missing a in end progrm right away, but here’s what happens with the tool:
2025-09-17 10:01:14 | INFO | __main__:_setup_logger:48 - Logger initialized
2025-09-17 10:01:14 | INFO | __main__:_initialize_llm:53 - Initializing Ollama with model: qwen2.5:14b
2025-09-17 10:01:14 | SUCCESS | __main__:_initialize_llm:55 - Ollama LLM initialized successfully
2025-09-17 10:01:14 | INFO | __main__:debug_fortran_code:331 - Starting Fortran code debugging process
2025-09-17 10:01:14 | INFO | __main__:debug_fortran_code:342 - Compilation attempt #1
2025-09-17 10:01:14 | INFO | __main__:compile_fortran:70 - Attempting to compile Fortran code
2025-09-17 10:01:15 | WARNING | __main__:compile_fortran:91 - Compilation failed
2025-09-17 10:01:15 | INFO | __main__:debug_fortran_code:358 - Code failed to compile on attempt #1, starting AI analysis
❌ Compilation failed (attempt #1). Analyzing error with AI...
2025-09-17 10:01:15 | INFO | __main__:analyze_error:121 - Analyzing compilation error with AI (attempt #1)
Compiler output is sent to the LLM :
error: Unclassifiable statement at (1)
error: Expecting END PROGRAM statement
LLM explanation:
2025-09-17 10:02:27 | SUCCESS | __main__:analyze_error:160 - Error analysis completed for attempt #1
🔍 ERROR ANALYSIS (Attempt #1):
==================================================
### Compilation Error Analysis
#### 1. What the error means in simple terms:
The compiler is expecting an `END PROGRAM` statement to properly close the program block but instead encounters the end of the file without finding it.
#### 2. Which part of the code is problematic:
The line `end progrm hello ! <- typo: should be "end program hello"` contains a syntax error due to a misspelling.
#### 3. Why this error occurs:
The Fortran keyword `END PROGRAM` must be spelled correctly for the compiler to recognize it as the end of the program block. The incorrect spelling `progrm` causes the compiler to not identify the intended termination point, leading to an unexpected EOF (End Of File) error.
#### 4. If this is a repeated attempt, explain why previous fixes might have failed:
If previous attempts at fixing the issue did not resolve it, it likely means that the typo was not corrected or there were other unnoticed errors in the code. Ensuring that `end program hello` is correctly spelled and placed is crucial for resolving this error.
### Summary
The compilation error occurs because of a misspelling (`progrm` instead of `program`) on line 3, which prevents the compiler from recognizing the end of the program block properly. Correcting this typo should resolve the issue.
==================================================
LLM proposed fix:
2025-09-17 10:02:27 | INFO | __main__:suggest_fix:178 - Generating code fix suggestion (attempt #1)
2025-09-17 10:02:35 | SUCCESS | __main__:suggest_fix:252 - Code fix suggestion generated for attempt #1
============================================================
PROPOSED CODE CHANGES:
============================================================
ORIGINAL CODE:
----------------------------------------
program hello
print *, "Hello, world!"
end progrm hello ! <- typo: should be "end program hello"
PROPOSED FIXED CODE:
----------------------------------------
program hello
print *, "Hello, world!"
end program hello
============================================================
You can then chose to keep this proposed fix or not, if so, the code will be recompiled and saved if it works, otherwise it goes back into the loop :
Do you want to apply this fix? (yes/no): yes
2025-09-17 10:04:02 | INFO | __main__:get_user_confirmation:312 - User accepted the proposed fix
🔧 Applying fix #1 and attempting recompilation...
2025-09-17 10:04:02 | INFO | __main__:debug_fortran_code:342 - Compilation attempt #2
2025-09-17 10:04:02 | INFO | __main__:compile_fortran:70 - Attempting to compile Fortran code
2025-09-17 10:04:03 | SUCCESS | __main__:compile_fortran:88 - Compilation successful!
2025-09-17 10:04:03 | SUCCESS | __main__:debug_fortran_code:352 - Code compiled successfully after 2 attempts!
✅ Code compiled successfully after 2 attempts!
✅ Fixed code saved to: fortran_mistakes/01_syntax_error.fixed.f90
2025-09-17 10:04:03 | INFO | __main__:main:431 - Fixed code saved to: fortran_mistakes/01_syntax_error.fixed.f90
For trivial bugs like this, the helper saves seconds. For trickier type mismatches, missing headers, or template errors, it can save minutes or even hours by translating obscure messages into direct fixes.
6. Reflections and Next Steps
Building such tool highlighted the fact that this could lower the barrier for newcomers who struggle with cryptic error messages as well as speeding up debugging by translating “compiler-speak” into natural language. Yet, it’s useful when you’re advanced, it allows you to stay focus in your workflow instead of bouncing between docs and forums and also feels interactive, almost like pair-programming. With that said, the current version is really simple and does not match the developer’s intent nor the coding standards of the code. Another challenge that araises is that some errors are too complex for a single pass even for multiple pass sometimes (especially on fortran interface compilers errors). Of course, it still needs human oversight — you can’t blindly trust every suggestion.
Looking ahead, tighter integration with build systems could make the tool even smoother, with fixes suggested inline rather than through a wrapper script.
Building this helper was less about replacing expertise and more about augmenting it. The LLM doesn’t make compiler theory disappear — it just makes the process of handling errors less punishing. Along the way, I realized how much of debugging is about translation: turning formal error codes into understandable, actionable steps.
Future improvements can be considered such as extending support for multiple compilers and languages. This can be useful when trying to port a code on different HPC machines. However it might required fine-tuning of the model which can get tricky but experimenting with fine-tuned models specialized for compiler outputs could improve the proposed solution and make them relie on your coding standards.
The journey suggests a bigger idea: compilers don’t have to be passive gatekeepers. With AI in the loop, they can become active teaching tools.
7. More autonomy in the community
Compiler errors have always been treated as obstacles to overcome, but they don’t have to be. By pairing a compiler with an LLM, we can reframe error handling as a dialogue rather than a guessing game.
The tool built is a small step in this direction — it decypher the compiler, explains what went wrong, proposes a fix, and lets the developer stay in control. It’s not perfect, but it shows what’s possible when we treat compilers less like blunt instruments and more like collaborators. Each of these paths brings us closer to a future where compilers don’t just enforce rules, but actively help developers write better code.
The tool described in this blog post can be found and used by clicking on the image below.
![]()