Table of Contents
- Introduction
- Data parallelism in PyTorch
- Distributed Data Parallelism (DDP)
- Efficient Data Loading
- Gradient Accumulation for Large Batch Sizes
- Mixed Precision Training
- Profiling and Optimizing Performance
- The easy way: PyTorch Lightning
- Slurm Script example
- References
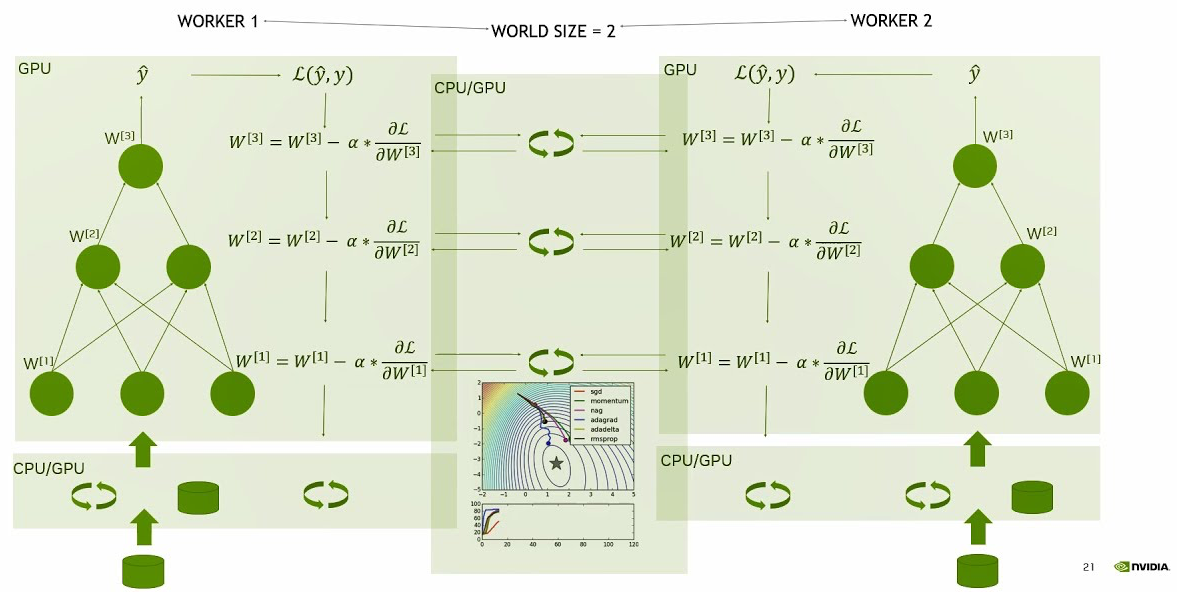
Illustration of Distributed Data Parallel (DDP) all-reduce operation in PyTorch. By NVIDIA
Introduction
Training deep learning models on multiple GPUs can significantly speed up your training process, especially for large-scale datasets or complex architectures. PyTorch offers flexible and powerful support for multi-GPU training through both data parallelism and distributed data parallelism. This guide will walk you through setting up multi-GPU training in PyTorch and provide useful tips to enhance performance.
Data parallelism in PyTorch
The simplest way to train a model across multiple GPUs is to use torch.nn.DataParallel. In this approach, the model is replicated across all available GPUs, and all processes are managed by the first GPU (also called the master process).
This method splits the input across the GPUs, computes gradients in parallel, and averages them before updating the model parameters on the master process. After the update, the master process broadcasts the updated parameters to all other GPUs.
Example:
import torch
import torch.nn as nn
import torch.optim as optim
# Define the model
model = MyModel()
# Move the model to the available GPUs
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
model = model.cuda()
# Define optimizer and loss function
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
# Example training loop
for data, target in train_loader:
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
Tip: DataParallel is not recommended for the following reasons:
- Overhead: While DataParallel is easy to use, it has some communication overhead due to waiting for all GPUs to finish the backpropagation, gathering gradients, and broadcasting the updated parameters. For better performance, especially when scaling to multiple nodes, use DistributedDataParallel (DDP) instead.
- Memory: The memory usage on the master GPU is higher than on the other GPUs, as it gathers all the gradients from the other GPUs. Thus if the you already have memory issues on a single GPU, DataParallel will make it worse.
- Scaling: Keep in mind that
DataParallelaverages the gradients across GPUs after backpropagation. Make sure to scale the learning rate accordingly (multiply by the number of GPUs) to maintain the same effective learning rate. The same applies for the batch size, the provided batch size to data loader is divided over the GPUs.
# Scale the learning rate and batch size
data_loader = DataLoader(dataset, batch_size=batch_size * torch.cuda.device_count(), shuffle=True)
optimizer = optim.Adam(model.parameters(), lr=0.001 * torch.cuda.device_count())
Distributed Data Parallelism (DDP)
For better performance, PyTorch provides torch.nn.parallel.DistributedDataParallel (DDP), which is more efficient for multi-GPU training, especially for multi-node setups. Indeed, when using DDP,
the training code is executed on each GPU separately, and each GPU communicates directly with the other, and only when necessary, reducing communication overhead. In the DDP approach, the role of the master process is heavily reduced, and each GPU is responsible for its own forward and backward passes, as well as parameter updates. After the forward pass, starting the backward pass, each GPU starts to send its gradients to all other GPUs, and each GPU receives the sum of all gradients from all other GPUs. This is called all-reduce operation *. After that, each GPU have exactly the same gradients and updates the parameters of its own copy of the model.
- * Reduce: A common operation in distributed computing where the results of a computation are aggregated across multiple processes. All-reduce means that all processes calls for a reduce operation to receive the result from all other processes.
Example:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.nn as nn
def train(rank, world_size):
"""Training function for each GPU process.
Args:
rank (int): The rank of the current process (one per GPU).
world_size (int): Total number of processes.
"""
# Initialize the process group for distributed training
dist.init_process_group(backend="nccl", rank=rank, world_size=world_size)
device = torch.device(f"cuda:{rank}") # Set device to current GPU
# Instantiate the model and move it to the current GPU
model = MyModel().to(device)
# Wrap the model with DDP
ddp_model = DDP(model, device_ids=[rank])
optimizer = torch.optim.Adam(ddp_model.parameters())
criterion = nn.CrossEntropyLoss()
# Example training loop
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = ddp_model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# Clean up
dist.destroy_process_group()
if __name__ == "__main__":
# Get the number of GPUs
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
world_size = torch.cuda.device_count()
local_rank = args.local_rank
# Launch one process per GPU
mp.spawn(train, args=(local_rank, world_size), nprocs=world_size)
- Important: This code should be executed on each GPU separately.
Tip: nccl as Backend
- NCCL Backend: For managing communication between GPUs during multi-GPU training, always prefer the
nccl(NVIDIA Collective Communication Library) backend overgloo(a library developed by Facebook) for GPU-based operations. NCCL is optimized for NVIDIA GPUs and ensures better performance and scalability, and Gloo is more suitable for CPU-based operations. For more details about the compatible operations with each backend, refer to the PyTorch documentation.
Launching Multi-GPU Training
Using torch.distributed.launch
To launch multi-GPU training with DDP, you can use the following command (on each GPU separately):
python -m torch.distributed.launch --nproc_per_node=4 train.py --local_rank <GPU_ID> # GPU_ID: 0, 1, 2, 3
--nproc_per_node: Specifies the number of GPUs to use per node.
This way is the old way, but still used, to launch multi-GPU training. The new way is to use torchrun:
Using torchrun
torchrun --nproc_per_node=4 train.py
Here you don’t need to specify the local_rank as it is automatically set by torchrun. And the mainscript is changed to:
if __name__ == "__main__":
world_size = torch.cuda.device_count() # or os.environ['WORLD_SIZE']
local_rank = int(os.environ['LOCAL_RANK']) # torchrun sets these environment variables
train(local_rank, world_size) # no need for the spawn function
Using srun
You can also use srun to launch multi-GPU training on a Slurm cluster. Inside a bash script replace torchrun with srun:
srun --nproc_per_node=4 train.py
However, the environment variables set by srun have different names than those set by torchrun. You can use the following code to get the local_rank and world_size:
if __name__ == "__main__":
world_size = torch.cuda.device_count() # or os.environ['SLURM_NTASKS']
local_rank = int(os.environ['SLURM_PROCID'])
train(local_rank, world_size)
Efficient Data Loading
Tip: Use DistributedSampler for Data Loaders when training with multiple GPUs using DDP, ensure that each GPU receives a unique mini-batch. This is achieved by using the torch.utils.data.DistributedSampler:
from torch.utils.data import DataLoader, DistributedSampler
# Create a DistributedSampler to ensure each GPU gets a different mini-batch
train_sampler = DistributedSampler(dataset)
# Create a DataLoader with the DistributedSampler
train_loader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=False, # Don't shuffle for distributed training (handled by the sampler)
sampler=train_sampler
)
- Important: Call
train_sampler.set_epoch(epoch)at the beginning of each epoch to ensure proper shuffling.
Tip: Pin memory and pre-fetch data for faster data loading. Use pin_memory=True and increase the num_workers in your DataLoader:
train_loader = DataLoader(
dataset,
batch_size=batch_size,
sampler=train_sampler,
num_workers=4,
pin_memory=True,
prefetch_factor=2
)
pin_memory=True: Copies data to pinned memory, which is faster to transfer to the GPU.num_workers: Sets the number of subprocesses to load data in parallel, avoiding I/O bottlenecks. It’s recommended to set this to the number of CPU cores available, but you can experiment with different values. Generally, a value between 2 and 4 is a good starting point. A high number of workers will increase memory usage.prefetch_factor: Sets the number of batches that each worker will prepare in advance.
Gradient Accumulation for Large Batch Sizes
If a given mini-batch of data is too large to fit into the GPU memory, you can reduce the batch size and update model parameters only after processing a set of smaller mini-batches and summing the gradients across them. This is called gradient accumulation.
Example:
accumulation_steps = 4
optimizer.zero_grad(set_to_none=True) # Reset gradients at the beginning
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.cuda(), target.cuda()
with autocast(): # Enable mixed precision if using AMP
output = model(data)
loss = criterion(output, target)
loss = loss / accumulation_steps # Normalize loss
scaler.scale(loss).backward() # Scale loss if using AMP
if (batch_idx + 1) % accumulation_steps == 0:
scaler.step(optimizer) # Update weights if using AMP
scaler.update() # Update scaler if using AMP
optimizer.zero_grad(set_to_none=True) # Reset gradients after each update
Tip: Use AMP for Gradient Accumulation
- AMP: Automatic Mixed Precision (AMP) can be combined with gradient accumulation to further optimize memory usage and training speed.
- Normalization: Ensure loss normalization by dividing by
accumulation_stepsto maintain gradient scale. - Zero Gradients: Always reset gradients after the specified number of accumulation steps to prevent gradient accumulation across updates. You can also use
optimizer.zero_grad(set_to_none=True)for less memory usage.
Tip: Monitor GPU Memory
- Memory Efficiency: When working with large models or datasets, use
torch.cuda.memory_summary()to monitor and optimize GPU memory usage. Tools liketorch.cuda.ampfor mixed precision training can also help reduce memory footprint.
Mixed Precision Training
Mixed precision training allows models to use lower precision (e.g., float16) for forward and backward passes, reducing memory consumption and speeding up training.
Example:
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler() # Automatically scales gradients
for data, target in train_loader:
data, target = data.cuda(), target.cuda()
with autocast(): # Enable mixed precision
output = model(data)
loss = criterion(output, target)
# Scale the loss and perform backpropagation
scaler.scale(loss).backward()
# Update the weights
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
Tip: Use AMP for Faster Training - AMP: Automatic Mixed Precision (AMP) can significantly speed up training by using lower precision (e.g., float16) for forward and backward passes, reducing memory consumption and improving throughput. - GradScaler: Automatically scales gradients to prevent underflow during backpropagation, especially useful when using gradient accumulation. - Zero Gradients: Always reset gradients after each update to avoid gradient accumulation across updates.
Profiling and Optimizing Performance
Tip: Use torch.profiler for Bottleneck Identification
PyTorch’s built-in profiler can help identify performance bottlenecks in your training pipeline:
import torch.profiler
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=2),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for i, (data, target) in enumerate(train_loader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
prof.step()
- Use TensorBoard to visualize profiling results and optimize accordingly.
Tip: Use NVIDIA Nsight Systems for GPU Profiling For more detailed GPU profiling, consider using NVIDIA Nsight Systems to analyze GPU utilization, memory usage, and kernel performance. Refer to the NVIDIA Nsight Systems documentation and to this post for more information.
The easy way: PyTorch Lightning
PyTorch Lightning is a lightweight PyTorch wrapper that simplifies the training process and provides built-in support for multi-GPU training, mixed precision, and distributed training. Here is an example of how to train a model using PyTorch Lightning:
Example:
import pytorch_lightning as pl
class LitModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.model = MyModel()
self.criterion = nn.CrossEntropyLoss()
self.optimizer = optim.Adam(self.model.parameters())
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
data, target = batch
output = self(data)
loss = self.criterion(output, target)
return loss
def configure_optimizers(self):
return self.optimizer
if __name__ == "__main__":
train_loader = DataLoader(...)
# Initialize the Lightning Trainer
trainer = pl.Trainer(devices=4, precision=16, strategy='ddp',num_nodes=2)
model = LitModel()
# Train the model
trainer.fit(model, train_loader)
PyTorch Lightning enables single/multi-GPU as well as multi-node training using a single codebase. The user only needs to set the Trainer configuration accordingly:
devices: Specify the number of GPUs to use. It can be set to'auto'for automatic detection.precision: Enable mixed precision training.strategy: Use Distributed Data Parallel (DDP) for multi-GPU training (more strategies).num_nodes: Specify the number of nodes for multi-node training.
Slurm Script example
If you are using Slurm to manage your training jobs, you can use the following script to launch multi-GPU training:
#!/bin/bash
#SBATCH --job-name=my_job
#SBATCH --nodes=1
#SBATCH --gres=gpu:4
#SBATCH --ntasks-per-node=4 # Important! It should be equal to the number of GPUs
#SBATCH --cpus-per-task=10 # Adjust as needed, useful for [data loading](#efficient-data-loading) (num_workers)
#SBATCH --time=01:00:00
#SBATCH --output=%x-%j.out # Standard output
#SBATCH --error=%x-%j.err # Standard error output
#SBATCH --comment="#tag"
# Load the required modules
module load cuda/version
# Activate your python environment
source activate my_env
# Run the Lightning training script
srun python main.py --num_gpus $SLURM_GPUS_ON_NODE \
--num_nodes $SLURM_NNODES \
<other_args>
- Important: Your main script should be able to handle the
--num_gpusand--num_nodesarguments (using argparse, refer to this post).
Keep it clean and efficient!
References
- PyTorch Distributed Training Documentation
- PyTorch Lightning Multi-GPU Training Documentation
- PyTorch Profiler Documentation
- Deep Learning with PyTorch: A 60 Minute Blitz
- Mixed Precision Training with PyTorch