
Photo Jimmy Ofisia on unsplash, the technical debt of a phone pole: each new line takes more time to add.
To exist, High-Performance Scientific softwares must overcome two specific challenges : “scientific validation” and “performance on bleed-edge and short-lived hardware”. Both require time, a high level of expertise, and the accumulation of many failed attempts. This explain why developers in this field are mostly experts in physical modeling or in high-performance computing, but incidentally almost none experts in the management of the technical debt.
Technical Debt is the implied cost of additional rework caused by choosing an easy (limited) solution now instead of using a better approach that would take longer (Wikipedia)
Once the code exists, just keeping up with the new physical edges cases / new HPC architecture - and often both - that popped up last month is the never-ending critical task. As a consequence, mainstream software challenges like “scaling up to a high number of users”, or “keeping a great user experience” are far from being critical.
This is why High-Performance Scientific softwares developers feel concerned about technical debt, but cannot put it on the top of the priorities list.
The CoE excellerat cares a lot about technical debt, because this is a key to transform high-potential HPC codes into high added-value tools for engineering design. So Let’s have a look: Is the situation really dire?
A primer on the DNA of a software : the codebase
The codebase of a software is the collection of human-written source code. The software executable is build on any machine from this unique codebase. In a way, the codebase is to a code what DNA is to a human.
The code-base is like a book written for both computers (to execute the action) and humans (to understand the action). It looks like:
ifld = 2
if(ifflow) ifld = 1
do iel = 1,nelv
do ifc = 1,2*ndim
boundaryID(ifc,iel) = bc(5,ifc,iel,ifld)
enddo
enddo
nek5000/src/connect2.f l113-119. Expressed in an Excel way, this snippet copies a subset of the sheet bc in a smaller sheet boundaryID, with iel the row ids. and ifc the column ids.
To understand the previous sample, one must know the language (here Fortran) and the context (what is behind these strange names such as ifflow). In all aspects, it is like reading a book. The usual readers here are the nek5000 developers community.
Several contributors add, change or delete lines in the book. The stream,of changes is irregular, with occasional “bursts” of additions (many lines added) followed by heaps of very small changes. One can get a good mental image of this with the animations of gource.
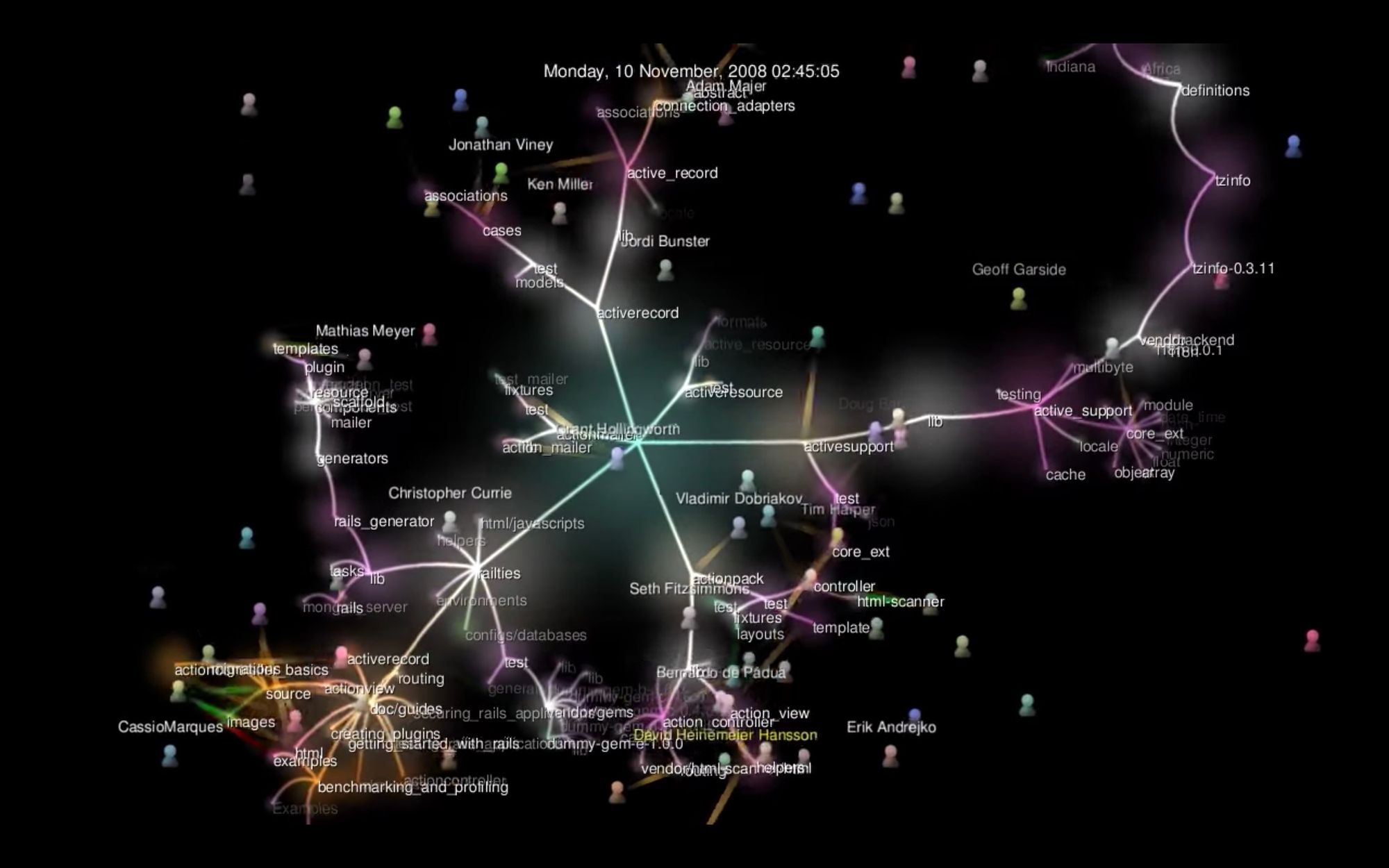
A codebase rendered by the gource projet, where developers look like bees building their home
The AVBP gource animation highlights the high number of concurrent developers working simultaneously on the same codebase. All these additions and deletions are safely recorded in a Version Control System, VCS. For scientific HPC applications, rich in failed attempts painfully corrected, the exhaustive history stored VCS is a priceless knowledge base.
Mining information in the history of actual codebases
We will use here some of the recipes of your code base as a crime scene written by Adam Tornhill, a programmer who specialized in code quality since 2010.
The codes under analysis are AVBP, Nek5000, two core CFD solvers part of COE EXcellerat, and neko, a modern version of Nek5000. All codebase history are sampled for 2019 Jan 1st ro 2022 Jan 1st
| VCS summary | AVBP | Nek 5000 | neko |
|---|---|---|---|
| folder | ./SOURCES/ |
./core/ |
./src/ |
| commits | 3451 | 136 | 1452 |
| nb. of authors | 115 | 22 | 9 |
| files | 1195 | 99 | 257 |
| lines of code | 351 796 | 65 806 | 50 382 |
| lines of comment | 83 327 | 16 075 | 11 006 |
| blank lines | 84 775 | 9 638 | 8 816 |
The code Churn
The first angle is the code churn. In Tornhill’s approach, this is the addition and deletion of lines over time.
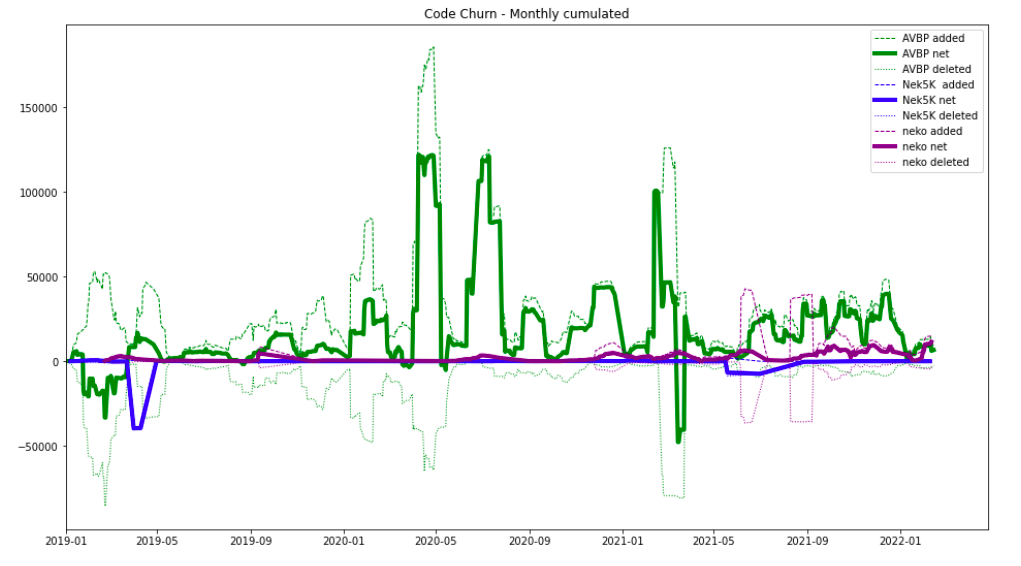
Code churn on AVBP, Nek5000 and Neko, over the past 3 years.
The data is created with git log commands and sorted with code-maat using the abs-churn analysis. Imported in a notebook, the churn is summed over 30 days to make the figure readable.
Due to the high number of authors, AVBP churn is dwarfing the two others. As the team are different in size, the same figure is normalized by authors, i.e. AVBP added lines are divided by 115, Nek 5000 by 22, neko by 9.
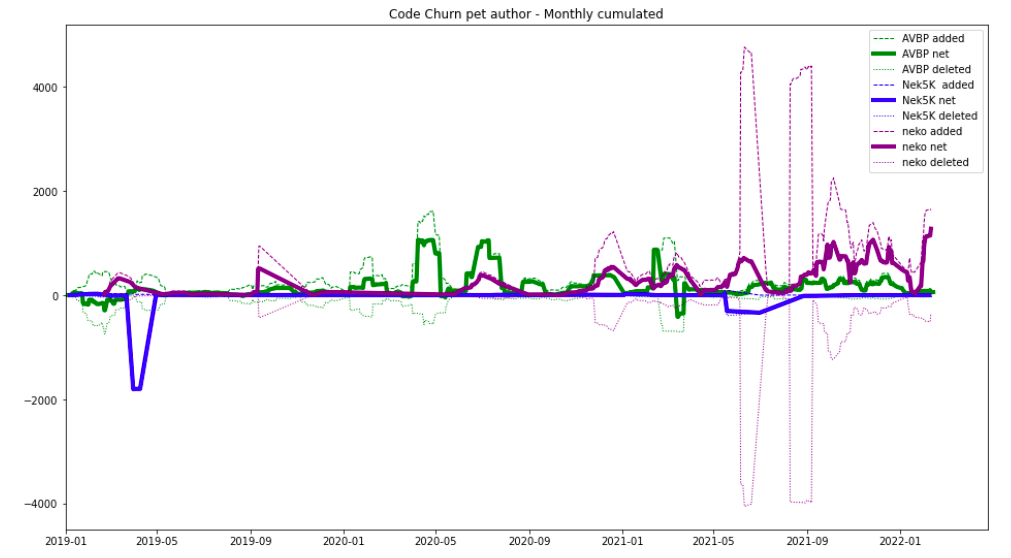
Code churn on AVBP, Nek5000 and Neko, over the past 3 years, normalized by authors
The most striking aspect is how the evolution of AVBP and neko are irregular, with deletions often in sync with additions. A global interesting fact on this dataset: for both AVBP and neko, for 2 lines added, one is deleted. Nek 5000 is almost not evolving anymore since 2019, apart from occasional cleaning.
Now if we cumulate the absolute churn over time, we see how much each code grow over 3 years
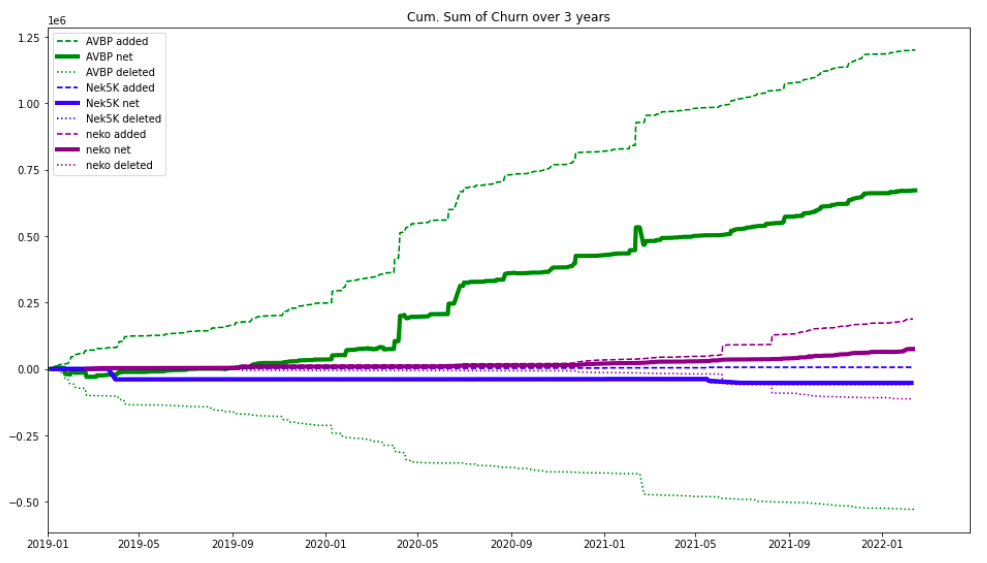
Cumulated Code churn on AVBP, Nek5000 and Neko, over the past 3 years
This figure highlights how fast the code is rewritten. On AVBP, a net addition of 10 000 lines per month is possible (which is probably bad news). The AVBP hyper-growth dwarves the growth of neko.
The code Age
The next figure is about the age distribution in the code.
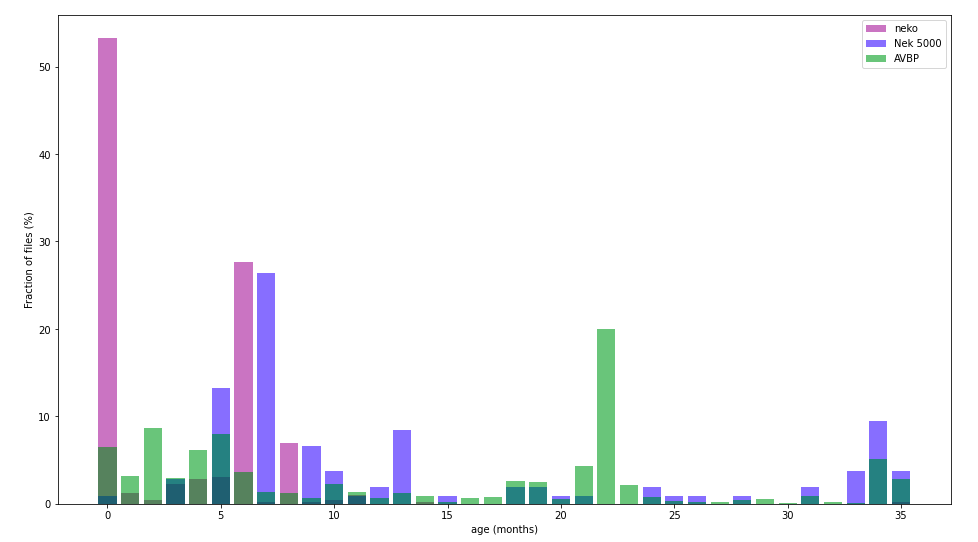 Repartition of files in the codebase, ordered by age (time since last modification)
Repartition of files in the codebase, ordered by age (time since last modification)
According to A. Tornhill, a “good age distribution” would be:
- A narrow fraction of the code is very young and actively modified, being the focus of the entire team…
- … supported by a large fraction of code aging without effort on support.
For a recent code, you can expect a large fraction of young, frequently modified code. This is well illustrated with the neko codebase. Young codes need time to stabilize. For an abandoned code, young files are rare or inexistent, showing nobody worked on it.
The AVBP codebase shows three groups. First only 10% of the code is more than 3 years old, like Nek5000 - it is probably hard to keep these codes running on more recent hardware without regular tuning. Then a large refactoring ( 30% ) occurred two years ago - and seems to age quietly. Finally, around 60% of the files are edited in the last 12 months.
The code complexity
Our last exploration will deal with the code complexity. A. Tornhill points that the number of code lines in a file/function is a good approximation of is complexity.
Regardless of the language, there is a limit on how many new lines a human can process. Depending on the sources, this limit is said to be in the range 50-200 lines. Typically, the popular Python linter pylint issues the too-many-statements when a function/methods is over 50 statements.
The next figure shows , for each file, the numbers of code revisions versus the size in lines.
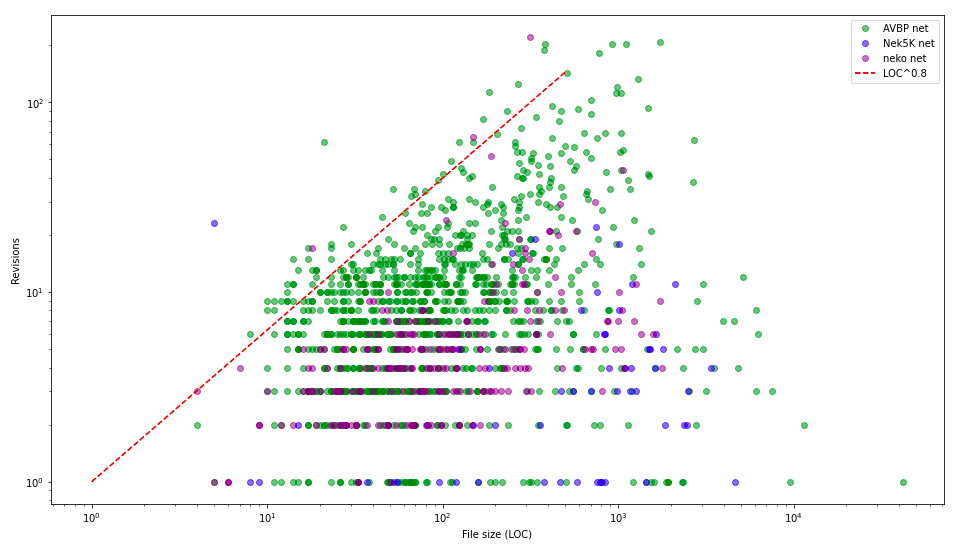
Revisions versus size, file-wise, for AVBP , Neko and Nek5000
This figure illustrates the general trend : “the larger the file, the higher the number of the revisions”. The files in the upper left corner are obviously interesting candidates for a focused refactoring. More quantitatively, files larger than 1000 lines that have been revised more than 100 times since three years have probably something to tell.
This analysis can even be pushed to the function/subroutine level. Here we use the tool lizard to scan AVBP and Nek 5000. This tool computes the cyclomatic complexity of code, i.e. the number of paths that can be followed when reading the code. According to Tom McCabe, the interpretation is the following:
- 1 - 10 Simple procedure, little risk
- 11 - 20 More complex, moderate risk
- 21 - 50 Complex, high risk
- 50+ Untestable code, very high risk
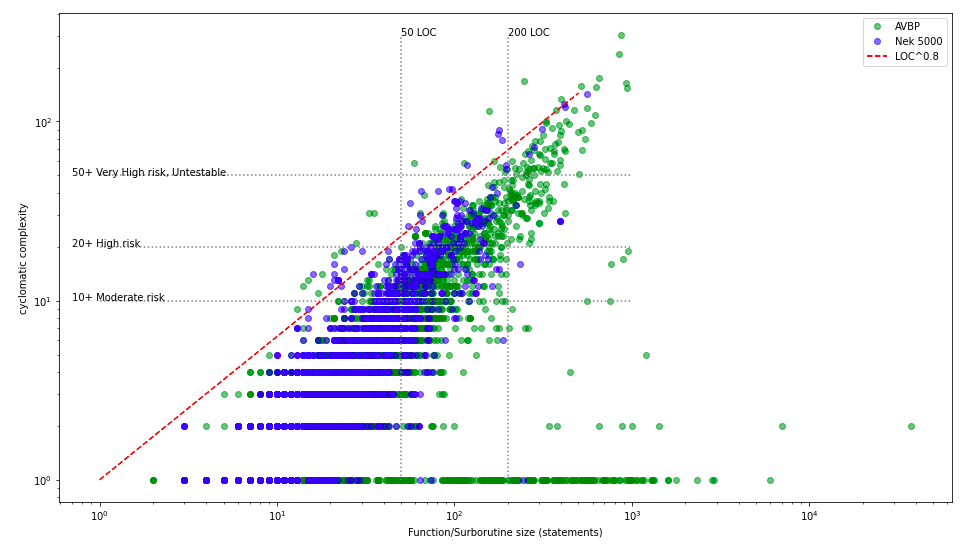
Cyclomatic complexity versus size, function/subroutine-wise, for AVBP and Nek5000
In this last figure, code elements bigger than 200 lines are either high or very high complexity. Almost no code element smaller than 50 lines are of high risk.
The whole scatter plot exhibits the same “shark tooth” shape for both codes. It looks like the two independent developers community respected a similar “acceptable” complexity, roughly below size^0.8 (the red curve). Obviously, this trait should be confirmed with many more HPC CFD repositories.
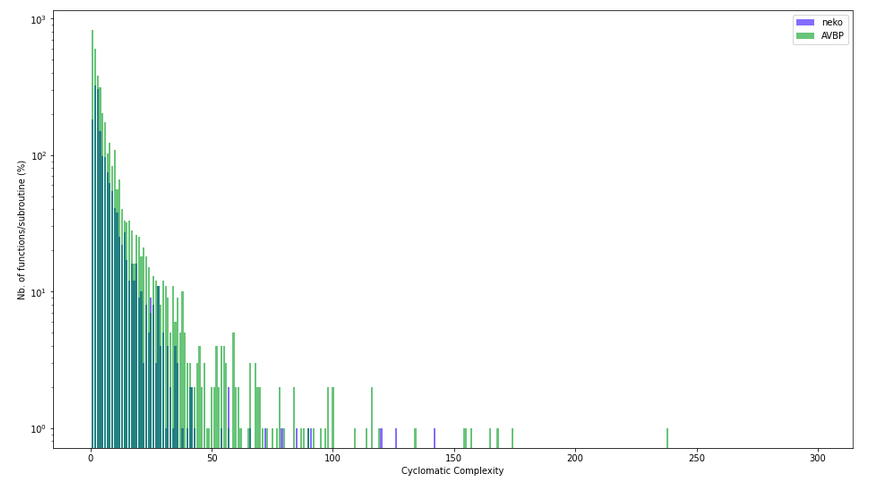 Distribution of files by cyclomatic complexity
Distribution of files by cyclomatic complexity
Scatter plots can be misleading, because the visual impact of many scattered point does not reflect the actual proportion of points. If we focus only on the distribution of cyclomatic complexity across the functions/subroutine, the most dangerous elements are relatively rare in the code.
| Cyc. Complexity | AVBP | Nek 5000 |
|---|---|---|
| >20 | 306 (9%) | 100 (6%) |
| >50 | 74 (2%) | 12/1678 (0.7%) |
Count of high and very high risk files
Note that in some cases, decreasing the complexity could lead to lower performance: compilers can have a hard time to inline szparated functions. A high complexity alone is not enough to put a function to the “most wanted candidates to refactoring”.
Takeaway
We have applied here several code base analysis techniques inspired from the work of Adam Tornhill on three CFD High Performance Computing solvers.
Both code churn and code age illustrated the high level of rework on these softwares. The code churn also showed the fast growth that can occur on active repositories up to 10000 LOC/month.
The revisions analysis outlined some very high frequency of rework on the same files, especially the largest ones. Complexity analysis confirmed the presence of numerous very high complexity code.
On the dark side:
- The constant growth, probably powered by the never-ending need to tackle more physically complex situations, could make the code un-manageable in the long run
- CFD HPC software codebases contains very high complexity code.
- As in this field, the expertise on modeling and numerics must take precedence over coding experience, large scientific HPC codes can struggle with the moderation of many low-experienced developers.
- For code Metrics : as each metric could easily interpreted in two different - and subjective-ways, the figures could fuel useless comparisons and community biases.
- these metrics should never become goals (see Goodheart law)
On the bright side, a Code Metric analysis could give some insights to the developer team. Narrowed to only one codebase without comparison, interesting assessments would still emerge, such as as:
- our code growth is four times bigger in 2019-22 than in 2015-18. Why this acceleration?
- this highly complex file only required 3 revisions in the 3 past years, so its is probably not worth our refactoring time.
- And the 10 worst files of the code (high complexity, high revision rates) are…
- Why these two files are highly coupled (often changed at the same time)
- Why these 3 GPU pragma are in the MODEL part, while the 12000+ other are in the NUMERICS part?
Acknowledgements
The authors wish to thank A Tornhill & his team and Terry Yin for bringing such investigations tools to the open-source community. A word of gratitude to the decisive action of our former teammate E. “Wonshtrum” Demolis who extended Lizard to Fortran.
This work has been supported by the EXCELLERAT project which has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No 823691.