
The Rosetta stone, by juxtaposing the same text in three languages, allowed a major leap in the understanding of the lesser know languages : the Demotic and Hieroglyphic scripts. In research, communities easily develop jargons, and Combustion research is no exception. One of the tasks of the Center of Excellence in Combustion (COEC) is to reach a mutual understanding at the technical level.
Introduction
While scientists usually understands each other on the theoretical thanks to publications, deciphering the way the other teams are is technically storing their data is a recurrent hassle. By juxtaposing their structure, the COEC will provide a common ground for understanding.
Introducing the SCHEMA description of data structures.
Format versus Data structure
The code AVBP is storing data using the binary HDF5 format. This explains how to read information, but not what to read.
Indeed, people can name the temperature of a fluid with various names : T, t, temp, Temperature, U. Moreover a temperature can be total or static, related to the gas or the liquid phase, in various units (°T, °F, °C), or worse, non-dimensioned.
Having only the format known is like masting the alphabet of a language. You can speak words, but not figure out their meaning, unless you have the dictionary. This dictionary is usually referred as a Data structure.
The CFD General Notation System (CGNS) is a clear example of Standard Data structure. CGNS is not compliant with reactive flow yet, due to the large rise in complexity of such systems. For example the same internal energy does not yield the same static temperature, depending on the thermodynamic data, or even the thermodynamic data interpretation.
The SCHEMA
The SCHEMA is a standard data structure notation system, initially used for JSON formatted data. It however can easily be used for other serialization formats.
Read here for more usages of SCHEMA in scientific applications
A typical documentation of temperature field in SCHEMA would look like this:
temperature:
type: object
description: Static temperature (Kelvins)
properties:
dtype:
type: string
value:
type: array
items:
- type: float
We see that the field is an array of items whose type is float. There is also the H5PY dtype or dataset type defining how the float value was stored.
There is finally a description manually added explaining the origin or purpose of the field.
Storage Variation across solvers
The SCHEMA information is an extensive description of the dataset. Comparing them would be tedious, but we can extract a big picture. In the following picture we show how similar data is stored for different solvers, namely AVBP, AYLES2 and Nek5000.
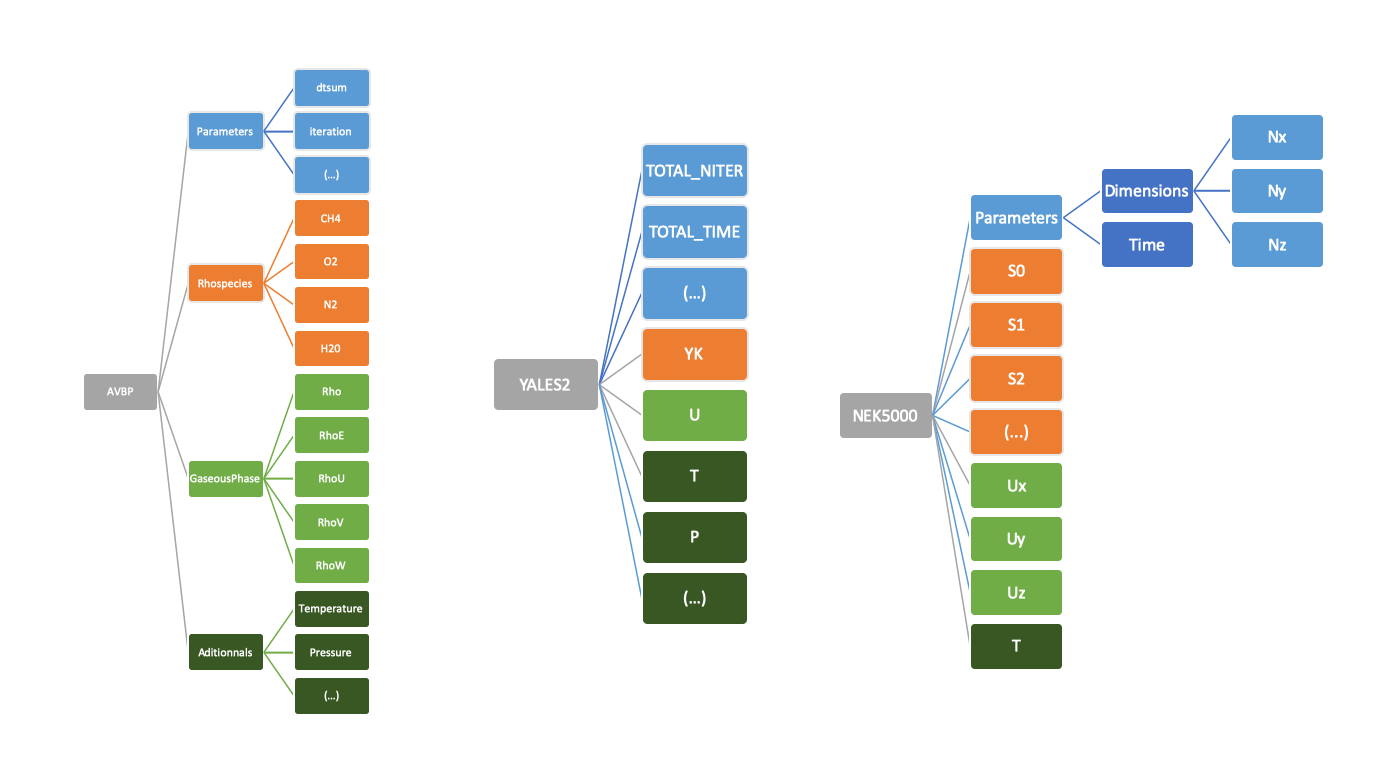
We can at least find three recurrent elements:
- There is often a Parameters (in Blue) giving global information on the dataset, such as the physical time and the iteration nb. associated to the data.
-
The gaseous flow is about the velocity components (in green). AVBP stores the conservatives variables, and put Temperature and Pressure in a separate Additional group, while YALES2 and Nek5000 include directly Pressure and and Temperature alongside Velocity.
-
The Species datasets (in orange) gives the composition of the reactive gas. It can be stored as a vector (Yk for Yales2) and sometimes need a correspondence table (Nek5000). Species concentrations seems to be mass fractions on all cases (it could have been volume fraction). A word of caution, AVBP stores RhoYk, in accordance to its conservative storage of the flow components.
This illustrates the need to explain, for each code where, what, and how the data is stored. Schema blueprints are now available for AVBP, Nek5000, YALES2, OpenFoam, and ALYA.
Practical access to data
The SCHEMA we worked until now helps to know what names are used for static temperature in the different codes. We will see in the following how to access to different data. What we want is to be able to load any field in a numpy array (for example) :
Temp = load_openfoam_ascii("./OpenFoam/OF_example/0.023", "T")
Temp = load_avbp("./AVBP/combu.init.h5", "/Additionals/temperature")
Temp = load_yales2("./YALES2/2D_flame.sol000004_1.sol.h5", "/Data/T")
Temp = load_nek5000("./Nek5000/premix0.f00001", "temperature")
Temp = load_nek5000("./Nek5000/premix0.f00001", "temperature")
Temp = load_alya("non_prem_box_VarVar_vectorized_00000010.pvtu","TEMPE", parallel_=True)
print(Temp.mean())
The imports needed are the following
"""
Module to show how to load fields from various solutions
"""
import os
import numpy as np
import h5py
import vtk # Alya pvtu
from pymech.dataset import open_dataset # Nek5000
A custom ASCII reader.
Here is a custom ASCII reader for OpenFOAM
def load_openfoam_ascii(time_folder, variable):
"""Fetch a field of openfoam as a numpy array"""
filename = os.path.join(time_folder, variable)
with open(filename, "r") as fin:
lines = fin.readlines()
start_idx = None
type_ = None
for i, line in enumerate(lines):
if line.startswith("internalField"):
start_idx=i
if "scalar" in line:
type_ = "scalar"
elif "vector" in line:
type_ = "vector"
else:
raise NotImplementedError("cannot read field of type : ", line)
nrec= int(lines[start_idx+1])
data = list()
for i in range(start_idx+3 , start_idx+3+ nrec):
if type_ == "scalar":
data.append(float(lines[i]))
if type_ == "vector":
clean_line= lines[i].replace(")","").replace("(","")
data.append([
float(item)
for item in clean_line.split()
])
out = np.array(data)
return out
I am not well acquainted with OpenFoam, and came up with a brute force parser. Please be kand and contact me to replace this with an official parser
An HDF5 reader
For HDF based data, the loaders are quite trivial, the only question being where in the tree the data was stored. So both for AVBP and YALES2 we have :
def load_avbp(solpath, variable):
with h5py.File(solpath, "r") as h5pf:
field = h5pf[variable][()]
return field
def load_yales2(solpath, variable):
with h5py.File(solpath, "r") as h5pf:
field = h5pf[variable][()]
return field
A Nek5000 loader
Nek5000 comes with pymesh, which allows an easy access with a good documentation.
The loader looks like:
def load_nek5000(solpath, variable):
dataset = open_dataset(solpath)
#print(dataset.data_vars)
return dataset[variable].data
A VTK loader
For ALYA we will use a pvtu loader. As VTK is vast and powerful, the loader I came up with is surprisingly complex. Again be kind and sent me simpler versions of this.
def load_alya(filename, variable, parallel_ = False):
# Create reader object
filetype = _get_vtkxml_filetype(filename)
if parallel_:
assert filetype == 'PUnstructuredGrid', "VTK file type does not coincide with user input"
reader = vtk.vtkXMLPUnstructuredGridReader()
else:
assert filetype == 'UnstructuredGrid', "VTK file type does not coincide with user input"
reader = vtk.vtkXMLUnstructuredGridReader()
# Read vtk file
reader.SetFileName(filename)
reader.Update()
# Obtain variable names
vtkdata = reader.GetOutput()
pointdata = vtkdata.GetPointData()
vars_num = reader.GetNumberOfPointArrays()
vars_name = []
array = None
for variter in range(vars_num):
name = pointdata.GetArrayName(variter).split()[0]
vars_name.append(name)
if name == variable:
array = pointdata.GetArray(variter)
if array is None:
msgerr =f"variable {variable} was not found among: {';'.join(vars_name)}\n"
raise RuntimeError(msgerr)
tmp_data = []
for ii in range(array.GetNumberOfValues()):
tmp_data.append(array.GetValue(ii))
out = np.array(tmp_data)
def _get_vtkxml_filetype(filename_, readmax_ = 5):
""" Function returning the filetype of a vtk xml file.
Input:
:filename_: input vtk xml file to check
:readmax_: int, max number of lines of file to search for the type
Output:
:myline: str, file type found
:Exception raised: in case file type not found
"""
with open(filename_, 'r') as fin:
for _ in range(readmax_):
myline = fin.readline()
if "type=" in myline:
return myline.split("type=")[1].split(' ')[0].split('"')[1]
raise ValueError("VTK xml File type not found, did you specify the correct file type?")
If you want to get a complete implementation of the VTK and Nek5000 loader, there is a VTK/Nek5000 to HDF5 converter in h5cross.
Acknowledgements
This work has been supported by the COEC project which has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No 952181 .