
Photo Martino Piertopoli on Unsplash
The path we try to follow this year at COOP
COOP focuses on transverse activities towards improving, optimizing and refactoring scientific codes at a sustainable pace.
First, if you are interested by Artificial Intelligence Activities (AI), and particularly Machine Learning for hybrid physical models, proceed to the HELIOS website.
Concerning High Performance Computing (HPC) and Computer Science & Engineering (CSE) activities, these are divided into four axes:
Bringing scientific tools to Safran Group, “Jasmine” (march) and “Kukicha” (sept.).
“Jasmine” (march) and “Kukicha” (sept.) are our bi-annual release of software to the Safran group. This is about the industrialization of our research tools -mainly combustion and CFD- towards a shareholder.
Why some industrialization in a research lab?
While we do care a lot about our shareholders satisfaction, there are two non-profit advantages for Cerfacs: The industrialization activity of COOP is, first of all, a research catalyst for research teams. The cycle is the following:
-
Upgrade a scientific tool, out of a research project to an engineering design tool, industrial proof.
-
Support the engineers in their day-to-day use of the tools.
-
Collect real-life experience and new situations
-
Build a new research project to tackle the new situation.
We clarified the AVBP versioning in use in a dedicated post:
“Road and Scouts semantic versioning strategy”.
Two generations of industrialized tools
Our industrialization products are currently relying on two sets of tools:
- The Opentea2 Suite is the Second generation of GUIs shipped to Safran. These tools are now in production with a High-TRL. The Opentea2 GUI is still powering production runs for the latest versions of the LES code AVBP.
- The Opentea3 packages are the third-generation of tools. The main advantage is a faster growth rate : deploying a new functionality can be done in a matter of hours, and advanced users can easily contribute. These packages provide more application-focused GUIs, and many non-GUI advanced tools. Read more about the Opentea 3 packages ecosystem.
Born several years later, the Third-gen. tools, albeit less mature, allow more advanced functionalities. In 2022, Both generations coexist in production for our customer.
Exascale Computing
For a global overview of today HPC market, read “Reinventing High Performance Computing: Challenges and Opportunities” review. Among the aspects presented, the rising share of GPU powered clusters is rising:
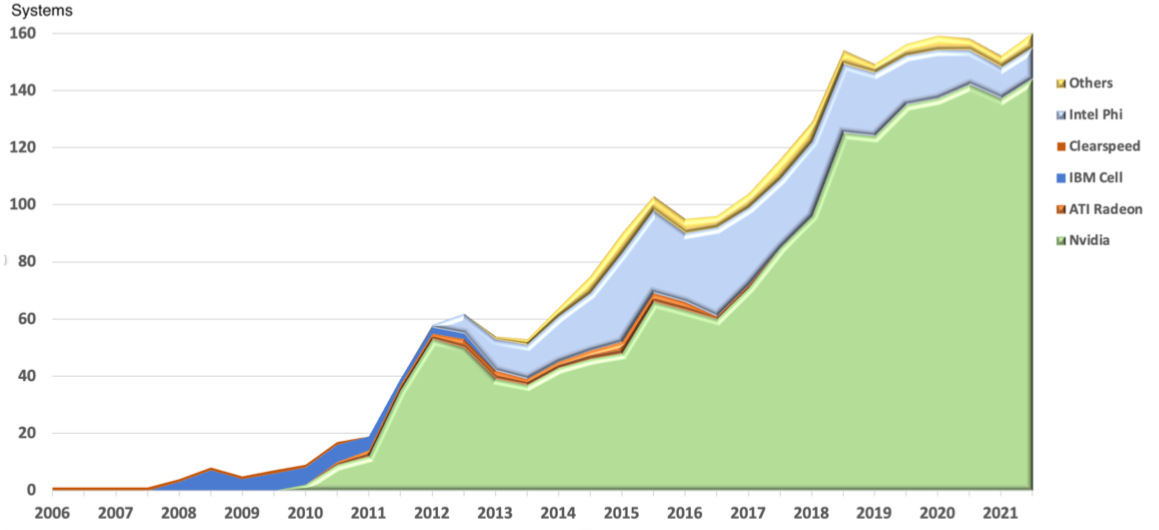
Systems Using GPU Accelerators on the TOP500, from “Reinventing High Performance Computing: Challenges and Opportunities”, Reed & Cannon & Dongarra, arXiv:2203.02544
As new HPC architectures are more and more complex,diverse, porting efficiently an HPC code manually gets less and less possible. As we aim for a single version of a codebase for many machine, a “translation” is needed to adapt this codebase to the architecture.
The translation step for exascale machine , in utopia, would be done by the compiler itself. This is a single step path codebase to architectureAwareAssemblyCode. Powered by projects like PROTEAS-TUNE, it will appear only after a long maturation and no HPC research team can wait that long. Moreover the C/C++ code will be the primary target over Fortran.
The current trend is “code generation”, it the sense of a two steps codebase to architectureAwareCodeBase to AssemblyCode. Several projects of various sizes are trying this approach:
- Legion is the Lawrence Livermore National Laboratory candidate.
- KOKKOS is the candidate of the US Department of Energy’s Exascale Computing Project.
- Small tools like Pystencils can create computing C/C++ kernels from stencils code definitions.
As the initial codebase need to be readable for non HPC experts, a more numerics-oriented language , or Domain Specific Language (DSL), can be created. Examples are LBMpy to generate various LBM solvers, of CEED’s Finite Element thrust for finite elements solvers.
This year, COOP will investigate both KOKKOS and Pystencils, which are sufficiently different to keep thinking out of the box of a single approach.
Code Metrics
The Center of Excellence Excellerat is ending this summer 2022. It allowed Cerfacs to open a new field : Code Metrics.
Following the work of A. Thornhill), the idea is to provide accurate information to HPC development teams : information on the code itself -sizes, complexity, dependencies, compliance to a custom writing standard- but also information on the team habits -sizes and frequency of commits, evolution of authors, growth rate-.
Here are some examples of discussions we hope to trigger with code metrics:
- our code growth is four times bigger in 2019-22 than in 2015-18. Why this acceleration?
- this highly complex file only required 3 revisions in the 3 past years, so its is probably not worth our refactoring time.
- And the 10 worst files of the code (high complexity, high revision rates) are…
- Why these two files are highly coupled (often changed at the same time)
- Why these 3 GPU pragma are in the MODEL part, while the 12000+ other are in the NUMERICS part?
Read more on what we worked on during jan/feb. with this post On the technical debt of High Performance Scientific Software.. This activity will continue in the frame of CoE COEC and, if successful, the sequel COE Excellerat II.
The elephant in the room of code development is the human aspect: A large and efficient HPC code is before anything the result of a vast human collective contribution to an abstract piece. This year, CERFACS will collaborate with several HPC code teams : CORIA (YALES2), BSC (ALYA), KTH (Nek5000), FAU (Welberla) to gather experience on how to interpret this information and what it can do for each team.
Trainings on software development
The COOP team will finally create training material and hold webinars on software development. These training will focus on the general good practices for scientific software development in a research context. The cycle will be structured as follows
General communication : raising awareness
The first element is a one hour webinar/presentation (40min pres./20min quest.) aimed to both technical and management people, to raise awareness on the following topics :
- An introduction to HPC software code bases : how does it grow?, when does it gets big?, why git?
- Four different persona who will eventually use your code, and why you should keep them in
- Using semantic versioning to prevent regressions, keep your versions in productions.
- What code metrics can tell about development team habits?
- What is code complexity, why is it a problem?
- What is statefulness?, data flow?, why being functional is nice sometimes?
Examples will be provided for Fortran, C/C++ and Python language. The content of this talk is however independent of the language.
Note: this content is not totally converged and might change in the next weeks.
Dedicated trainings
Once the general talk is ready, COOP will provide advanced training on each sub topic, with various formats:
- Written posts, like this post on the versioning of an HPC code for industrial users.
- Do it your self Jupyter notebooks.
- Short concept-focused talks, like this simple git mental model
Achievements
- See the webinar “FEniCS at Cerfacs: lessons learned” from Luis F Pereira (Cerfacs/COOP).