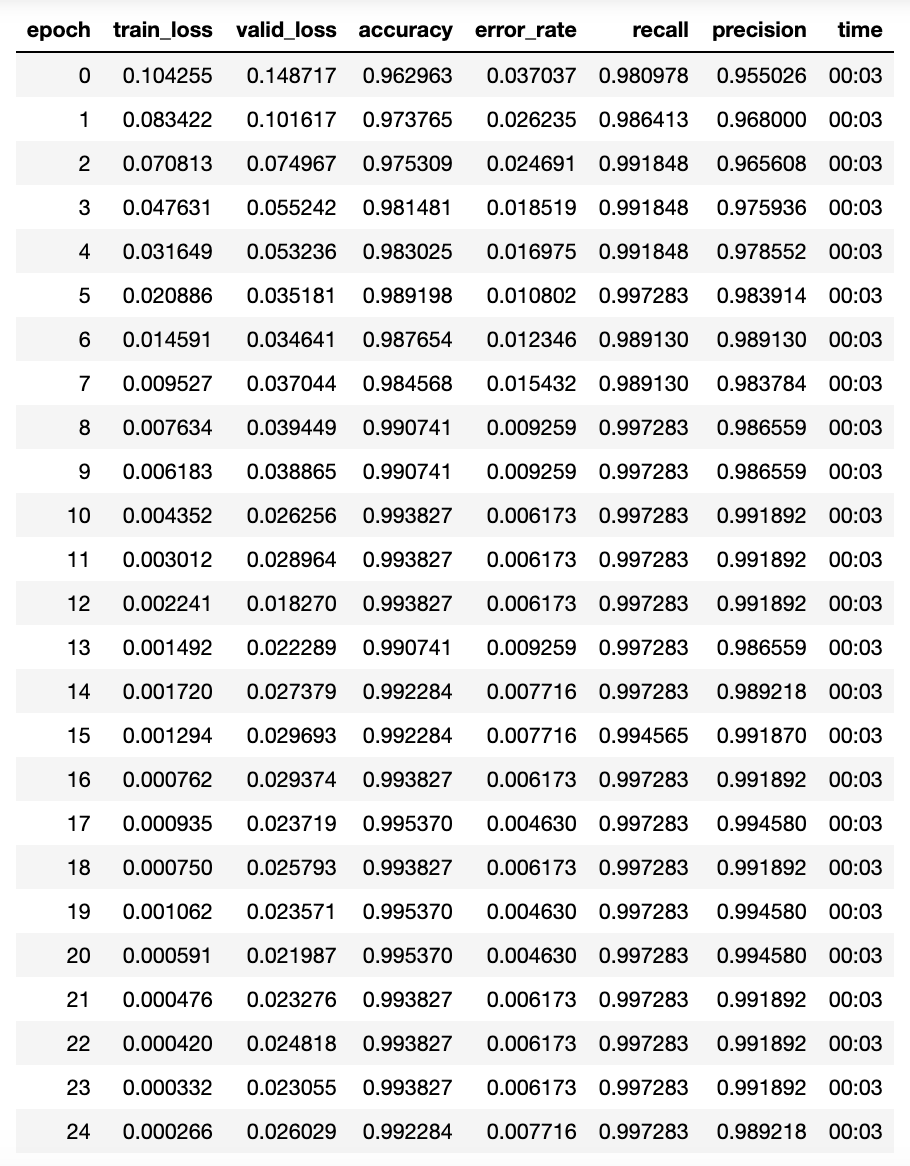
This project aims at helping the current program of bear re-introduction in the Pyrénées mountains, by developping an automatic bear detector that will trigger some scaring device, in order to protect sheep from bear attacks.
 Sample of images taken by one of the camera trap set by the OFB.
Sample of images taken by one of the camera trap set by the OFB.
Foreword
Governmental organizations started reintroducing the brown bear in the French Pyrénées in 1996. The population remains very fragile as bears are targetted by hunters and are subject to allegations that they cause a lot of damage to mountain pastures, for example in the case of a fall of a hundred sheeps in 2016. Damage caused by bears is indeed estimated to 1200 sheep per year and only on the french side of the Pyrénées. The french government has voted a vast program for the defense of the brown bear starting from 2018 up to 2028 to help work on different axes for the brown bear defense. One of them is to help protect pastures with shepherds as mentioned on their website.
It also involves research funding for “automatic shepherds” which consist of triggering frightening devices when the approach of a bear is detected. Actors on this subject are the DREAL which is the french bureau for industrial and natural risks, the OFB and the DDT, who are both responsible for biodiversity conservation and actual developments of departments in the Pyrénées.
Objective
The DREAL provided us pictures taken on the field of all the wildlife that can be encountered in the mountains. The objective of the project is to train a neural network to recognize a bear amongst all of the other animals that are likely to be passing by. Once trained, the neural network will be exported on a portable computer that will be connected to a camera trap. When an animal is passing by, a picture will be taken and analysed by the neural network (this is called inference). The inference result, bear or not bear will trigger, or not a frightening device.
The choice of deep learning
Deep learning and convolutional neural networks (CNN) are very effective in image treatment. The CNN will analyse the picture and perform a convolution operation on it. This will reduce the size of the image whilst enhancing top features such as fur patterns, eyes or ears in the last layers in the neural network. Since eyes, ears of animals have already been an object of work for several existing CNNs that exist online, it is possible to use pre-trained networks that will avoid our neural network the difficult task to have to learn again to recognize an eye or an ear, a tree from the background, a grass, etc. This is called transfer-learning. This leads us to the workflow below that represents a classical deep learning project.
Deep learning architecture
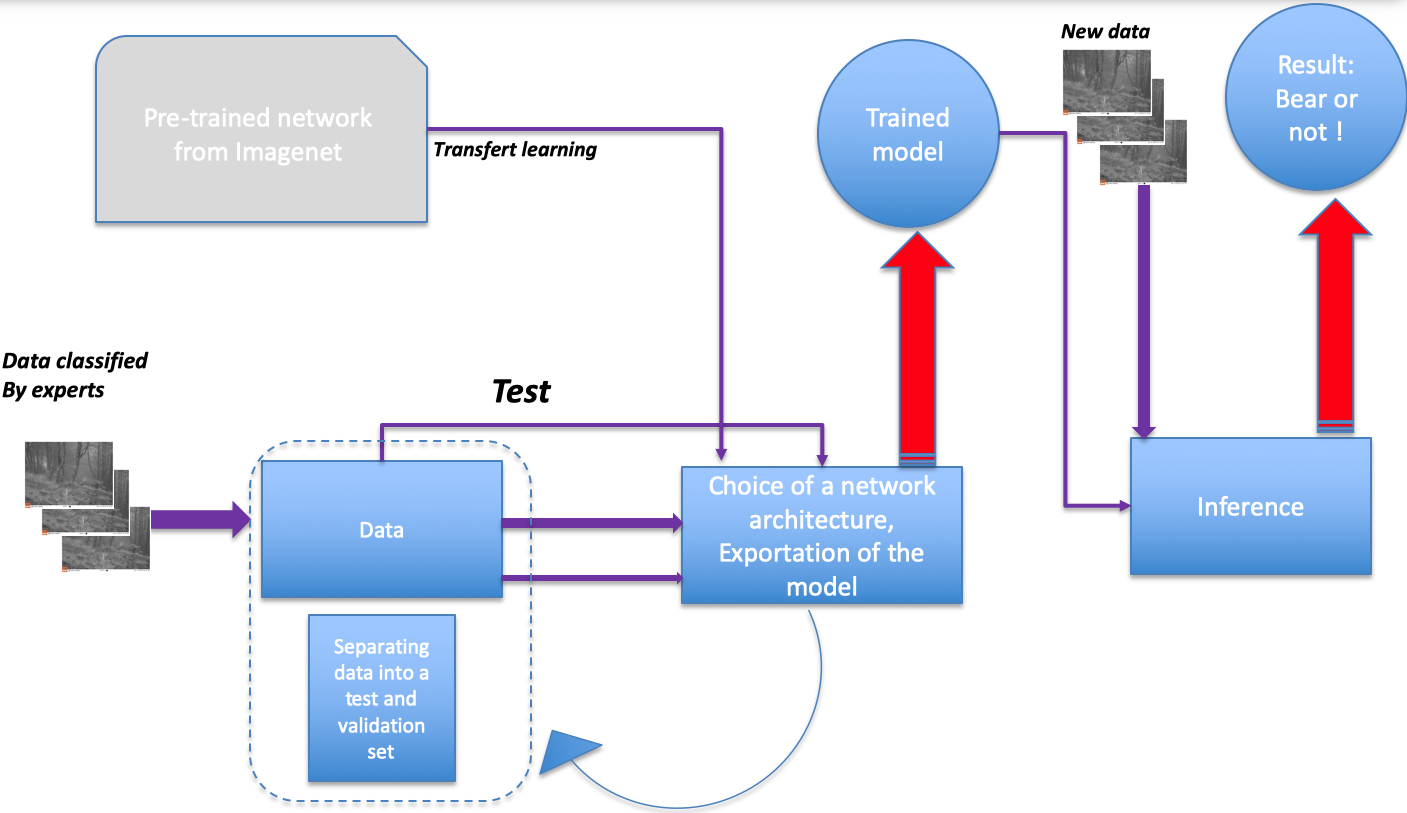
The CNN will be trained on the images that have been labeled by experts and classified into species. The CNN will be using pre-trained weights coming from ImageNet. It means that we don’t have to train all the layers from our neural network but only the one that leads to our final output (which is bear or not). The pictures that the network will be trained on are divided into a training set and a validation set. For these two groups, the labels are known. This is called supervised learning. At each epoch we will have trained the network on all the batches of pictures of the training set, the neural nework will be tested for accuracy on the validation set, and each time some correction into the weights of the neural network will be done thanks to adjusting the performance given by comparison to the labels of the validation set.
Data preparation
The DREAL works together with the OFB and together they set a lot of camera traps in the mountains to be able to capture images of the wildlife and get statistics out of it. The data coming from these camera traps are gold for a deep learning data scientist. We have in our hands close to a hundred thousand images of all the species wandering in the forests and the mountain pastures, encountering camera trap on their way, and haven their picture taken of, without even noticing it most of the time, and more importantly, not being disturbed. Data provided was classified by experts from the OFB and standed in various folder trees with several locations.
Data formatting
The folder at the end of the tree, though, is almost always named by the species name. After finding unique occurences to designate species, it is possible to generate the files in a format that the deep learning model will accept, by that I mean a csv file, containing path, and label. The network takes in pictures that have to be at least 224*224 pixels, since we have about 60k images to test on, it will be too long so we convert the images to numpy arrays.
Code for converting images into numpy arrays
from keras.preprocessing.image import load_img, array_to_img, img_to_array
channels = 3 #RGB
image_width = 224
image_height = 224
dataset = np.ndarray(shape = (len(list_images),image_height, image_width, channels), dtype = np.float16)
dataset = [img_to_array(load_image(list_images[i]).resize((224, 224)))/255. for i in range(len
(list_images))
np.save('images.npy', dataset)
The network is trained on a cleaned dataset from 2019 and 2020, containing 3241 images among them 1258 bears. The pictures were cleaned from pictures from the year 2019, and the bears were filled in with more pictures from the year 2020.
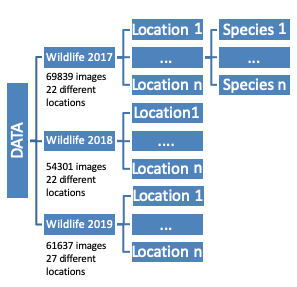
Original format of data received by the french bureau.
With so much data in our hands, we could not resist to get some statistics out of it!
Statistics
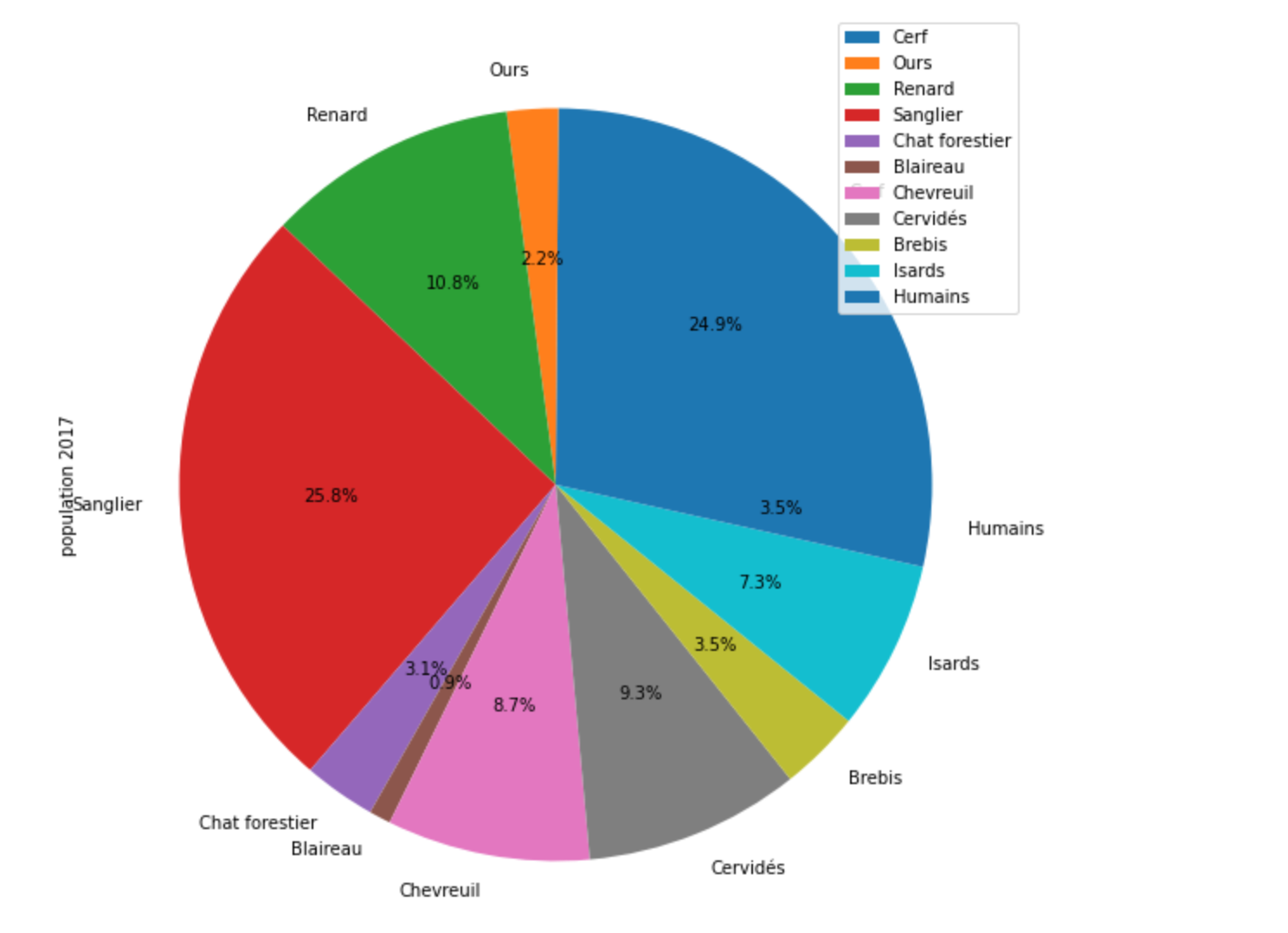
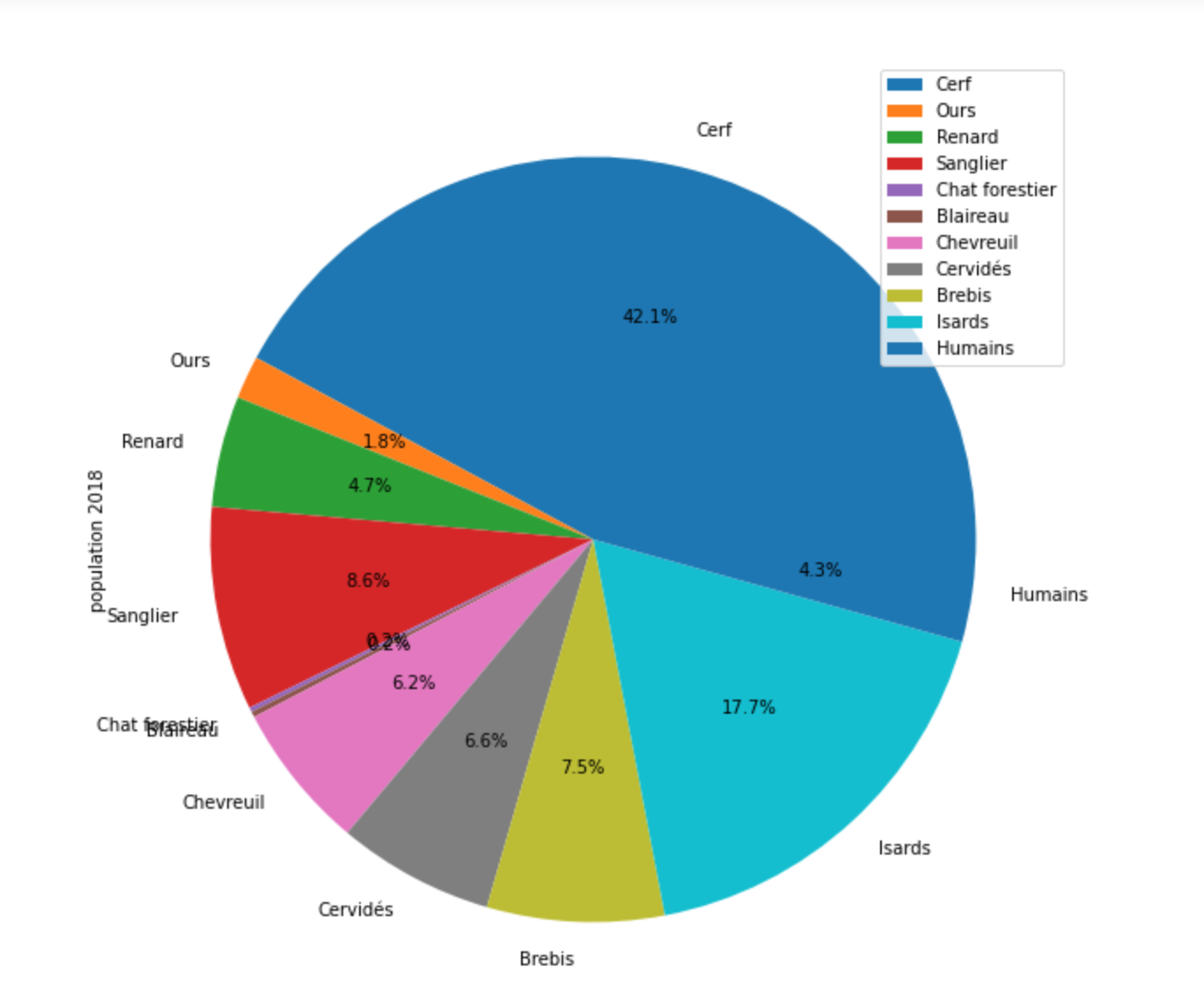
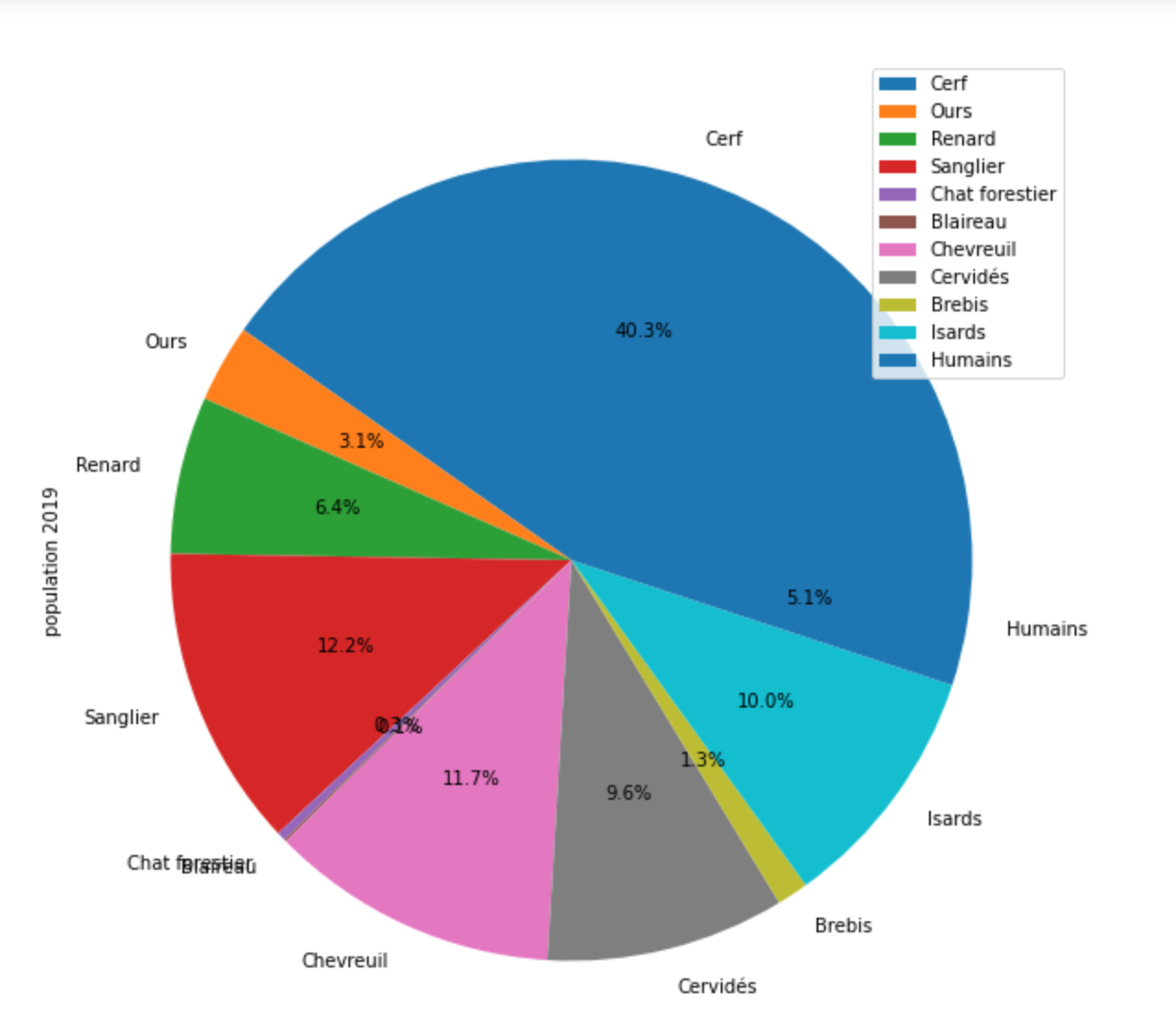
Statistics of predominant species in the Pyrénées in 2017, 2018 and 2019.
We can follow here the evolution of the population of various species from 2017 to 2019 for example. But as it can be seen the proportion of bear pictures is quite small compared to the total pictures of animals. To deal with this issue, the network will be trained on an equal proportion of other animals and bears, by feeding the bear database with pictures coming from other years and only taking a sample of pictures from other animals from only one year.
Deep learning architecture
Fastai is an opensource API developed by Jeremy Howard on PyTorch. It is very well adapted to image classification.
For the network architecture we will choose a classical CNN with a ResNet of 18 layers.
The ImageDataBunch class from Fastai creates automatically the validation test data from a percentage chosen in the parameters.
np.random.seed(42)
data = (ArrayImageList.from_numpy(dataset_train)
.split_by_rand_pct(0.2)
.label_from_array(label_train)
.databunch().normalize(imagenet_stats))

Class ImageDataBunch from fastai.
The validation set contains 20% of the total number of pictures, 648 items, and the network is trained on 2593 items. Images have 3 channels (RGB), and have the size 224*224.

Visualization of a sample of the ImageDataBunch.
learn_bear_vsall = cnn_learner(data, models.resnet18, pretrained = True, metrics=[error_rate, accuracy] )
Visualization of a sample of the ImageDataBunch.
Fastai has a built in function that helps improving the hyperparameters for the training, here is the optimization of the learning rate:
learn_bear_vsall.lr_find()
learn_bear_vsall.recorder.plot()
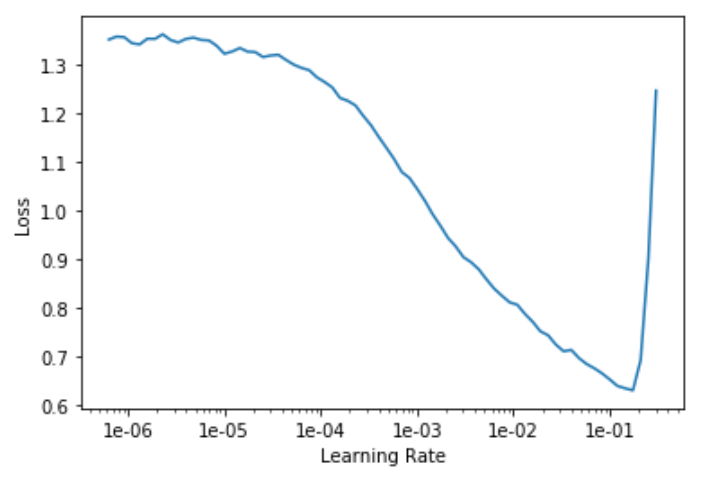
Learning rate plot.
This plot shows that the optimal learning rate is around 1e-2.
We can re-run the training with this learning rate:
learn_bear_vsall.fit_one_cycle(1, max_lr = 1e-2)
By default, fit_one_cyle function of fastai is freezing the layers that are pre-trained.
Then we unfreeze and rerun the learning rate optimizer.
learn.unfreeze()
learn_bear_vsall.lr_find()
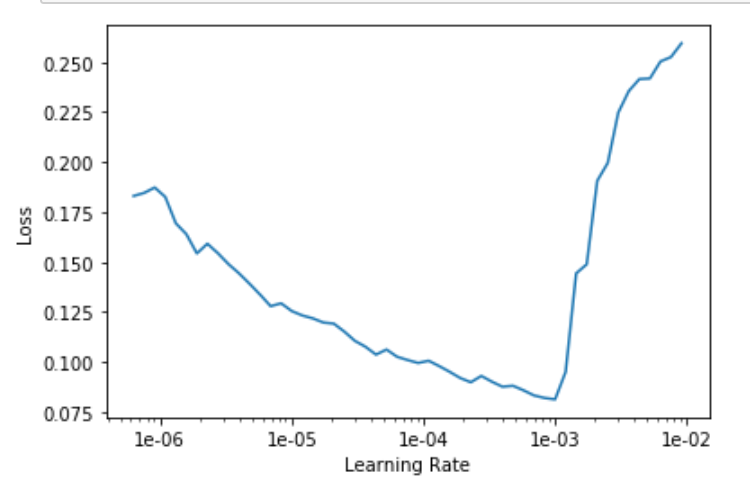
Learning rate plot after unfreezing the model.
The model is now training the whole layers of the model.
learn_bear_vsall.fit_one_cycle(100, callbacks=
EarlyStoppingCallback(learn=learn_bear_vsall,
monitor = 'accuracy',
patience = 10), max_lr=slice(1e-6,3e-4))
Since the classes of bear and others are well balanced, we can choose accuracy as a metric for evaluating the model performance:
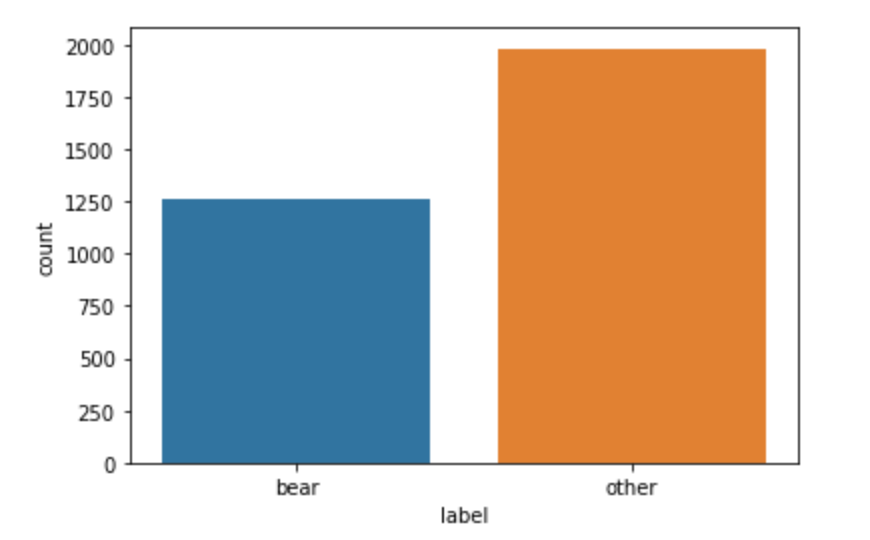
Evaluation of the balance between classes.
We cant plot the losses during training and check for overfitting:
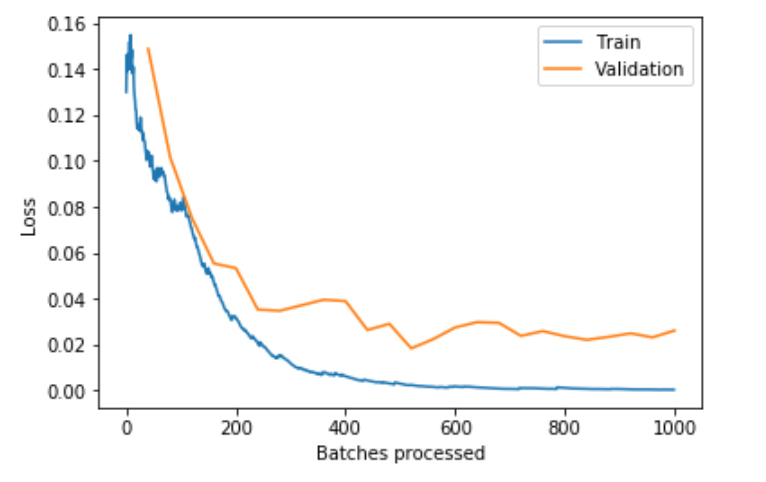
Now let’s study the performance of the test.
interp = ClassificationInterpretation.from_learner(learn_bear_vsall)
interp.plot_confusion_matrix(figsize = (5,5))
Binary classification
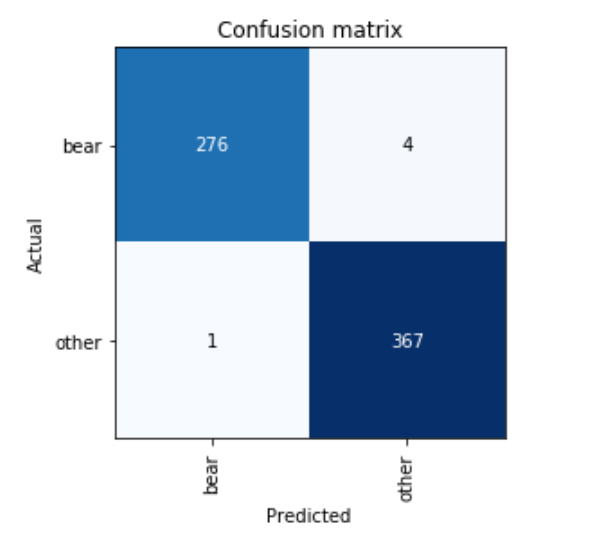
Confusion matrix on the validation set.
Image on the diagonals are well detected, we can see that 276 bears have been well labeled and 367 others have been well labeled. There are four bears that were mistaken for others and 1 other was mistaken for a bear, which can be also known by the python command:
interp.most_confused()
which gives the answer:
[('bear', 'other', 4), ('other', 'bear', 1)]
Failures
The top most confused images badly identified by the network can be looked at to improve the network, it can be seen that falsely labeled images are images where there is no animal to be found. This is due to either:
- badly classified images
- the choice of setup for the camera trap that takes several images when a motion is detected with a time delay, which leads to a picture taken each time at the end without any animal. If they are labeled, it can induce a high error rate in the network training.
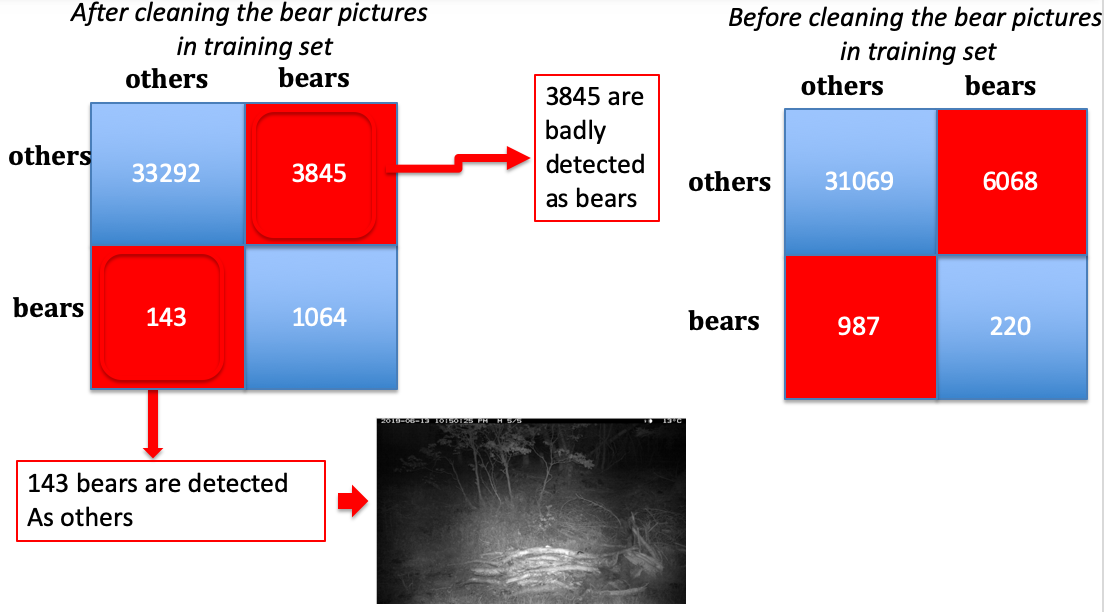
We can see that if the training data are cleaned (which means removing the images labeled as bears where there is nothing), the confusion matrix is highly improved. Before cleaning, 987 bears are classified as others, whereas 143 bears are classified as others after cleaning the training data. Of course, the test data of about 38k images is not cleaned, so the misclassified images that remain are most empty images labeled as bears.
Deep learning architecture.
Another failure case is shown here: Among these three images, one is detected as another, and the highlighted pixel show that a shape in the snow is responsible for that.

Example of the advantage of analyzing a sequence of pictures.
In this case, two bears were detected with a very high confidence rate, but when the bear stands, the network gives an inference result of about 45% that leans for the class other. Though the pictures taken before were detected perfectly. This case could be easily avoided if we analyse a sequence of images. This means getting the horodata of the metadata of the pictures and classify the images according to their sequence instead of image per image.
interp.plot_confusion_matrix(figsize = (5,5))
Now that we have developped a model trained on a small batch of images , we want to test it on a big set of images.
Multi-class classifier
The multi-class classifier is not only making the distinction between a bear and and the “other” category, but is also able to make the difference between a fox and a forest cat, or a deer.

Sample of images keeping various species
The confusion matrix shows here there are 19 different species and can highlight which species are bringing the most confusion. For example in this case, a human was misclassified with a dog, which is a picture where the picture contains both
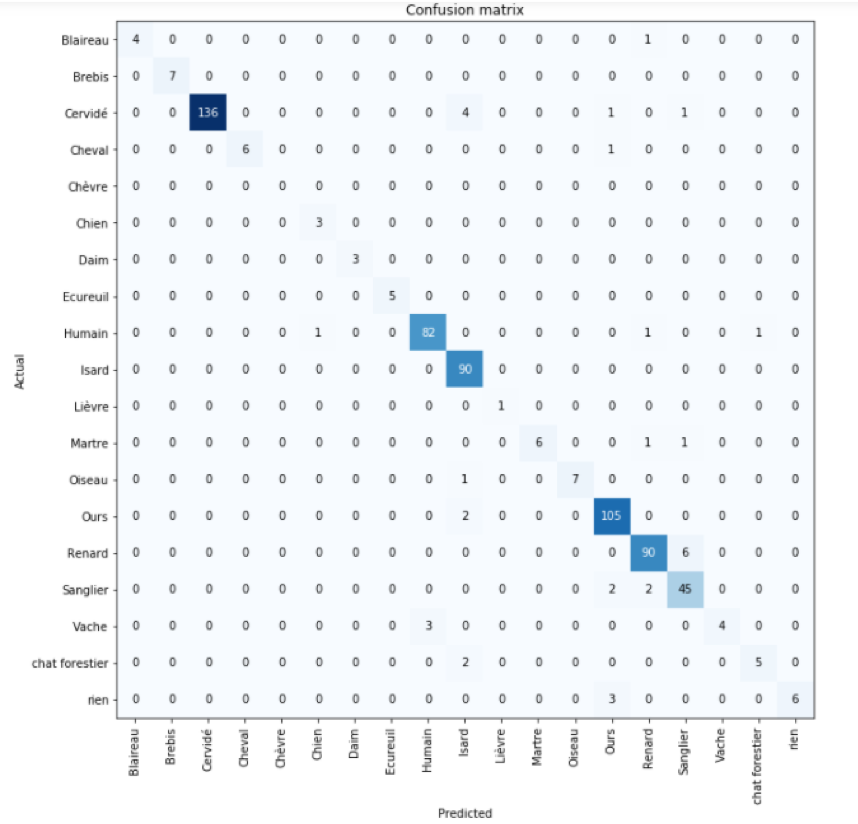 Confusion matrix obtained on a sample of pictures
Confusion matrix obtained on a sample of pictures
The application of that is that it is possible to automatically classify images and save hundreds of hours of human work.
Exporting the model and making inferences
The model can be exported by the command:
learn_bear_vsall.export()
This will generate a pickle file at the location where the command is run.
The images are uploaded by the numpy file and labels are loaded from the csv file.
Inference
Once the model has been trained and verified as shown above, a picture can be loaded and the model can be called, as it will be the case in the wild:
The model gives an output with a label and an associated confidence rate.
Though the model has to be trained on a GPU, the inference can be made on a CPU.

This is the bulk result given by the neural network:
- the output class reaching the highest percentage rate.
- the confidence rate given in percent for each class, here 68% for the bear class, 32% for the class ‘other’.

The author wishes to thank M. Henri Toulotte from DREAL, Corentin Lapeyre, data-science expert, and Isabelle d’Ast for technical support for libraries installation on the CERFACS clusters.
![]()
![]()