Reading time 12 min.

Large HPC Fortran codes are like a family of ancient giant sequoias in the forest of scientific softwares
The EXCELLERAT Centre of Excellence includes several High-Performance Computing (HPC) laboratories that are preparing and promoting the use of HPC for engineering in the future. The project focuses on the softwares that will run on the next generation of hardware, “Exascale” computers.
Surprisingly, five out of seven core codes used for this exploration use Fortran, a language born in 1954. Moreover, three are more than twenty years old, and the largest of them started in the 1990s:
| name | language | started in |
|---|---|---|
| Nek5000 | Fortran | 1990 |
| AVBP | Fortran | 1993 |
| Fenics | C++/Python | 2003 |
| ALYA | Fortran | 2005 |
| Fluidity | Fortran (40%) | ? |
| TPLS | Fortran | 2009 |
| Flucs | C++/Python | 2012 |
If you consider the typical turn-over in labs, PhDs candidates can invest three to five years at the maximum. HPC supercomputers show a similar lifecycle. In terms of longevity, these codes have survived from two to six generations of hardware and lab personnel.
Why do physicists use Fortran to prepare Exascale computing?
Fortran has been popular among physicists since decades. The article ‘why physicists still use Fortran?’ gives an overview of the reasons.
However, we are not talking here about just any academical software. The peculiar aspect of this software is the objective of promoting the use of HPC research software in engineering decisions. In other words, all software on the list has already demonstrated:
- Good performance, with respect to the HPC community
- Proper physical modeling, with respect to the physical community
- Acceptable accuracy, with respect to the numerical community
- A large enough application field, to attract engineering users.
- Satisfactory user experience, to not scare these users away.
The regular trainings on Fortran Modernization (e.g. the Numerical Algorithm Group (NAG) Fortran Modernization workshops) are part of the solution. However, the more recent - and trendy - approaches (C++ templates, HPC domain specific Languages) are supported by relatively larger communities. Therefore, in terms of training resources, Fortran is outnumbered.
How has Fortran kept these huge warships afloat?
Pushing further longevity and performance
Before developing, we need do understand the structure of this software.
The fabric of scientific solvers: source code
A scientific solver is - usually - a very simple single component. You insert a bundle of data at the input, the black box hums for a while, then delivers heaps of data at the other end. What can we see if we open the top of this black box? Is it scary?
Inside the black box, you only find the source code, translated for the computer. Mere humans work on the code through the source code, and it looks like this (sample for the GitHub of Nek5000):
if (icalld.eq.0) then
! just in case we call setup from usrdat2
call fix_geom
call geom_reset(1)
call set_intflag
call neknekmv
if (nid.eq.0) write(6,*) 'session id:', idsess
if (nid.eq.0) write(6,*) 'extrapolation order:', ninter
if (nid.eq.0) write(6,*) 'nfld_neknek:', nfld_neknek
nfld_min = iglmin_ms(nfld_neknek,1)
nfld_max = iglmax_ms(nfld_neknek,1)
if (nfld_min .ne. nfld_max) then
nfld_neknek = nfld_min
if (nid.eq.0) write(6,*)
$ 'WARNING: reset nfld_neknek to ', nfld_neknek
endif
endif
There is obviously a lot of jargon but Fortran keywords are easy to spot and quite explicit : if, call, endif… While mainstream computer science can deal with an endless list of action (database queries, text processing, 3D rendering, security, etc…), these codes involves only computation and memory access. Therefore, you do not really need a computer scientist nor a general purpose language to write these codes … but you need numerics, physics, and HPC experts… and lots of them.
Looking at the structure of the fabric
The source code is a lot of lines, nested in a typical structure.
- These lines are grouped in blocks (Usually Subroutines, Functions or Module in Fortran)
- The blocks are gathered in files. (Usually .f or f90)
- The files are grouped in directories
The following figure gives you an overview of the code AVBP illustrating this nesting with circular packing.

Repartition of AVBP source code
The largest circle is the root folder of the source code .. In the first circle, the darker circles represent several subfolders : ./NUMERICS, ./PARSER, ./IO, etc…
The nesting continues down to the darkest and smallest discs, each standing for one subroutine or function. For the example, the subroutine hdf_kewordsinside ./IO/hdf_kewords.f90 is highlighted with a white circle.
The relative size of the circles is proportional to the amount of lines inside.
You can grasp with this figure, the variability and nesting of the source code, the very material each one will edit. These characteristics are specific to each code. The very same image for the core folder of Nek5000 looks quite different, without any nesting.

Repartition of Nek5000 source code
How big are the codes?
Now comes the scale. The “large” codes are made from 100 to 1000 thousands of lines. This is small compared to large commercial software and development teams over one hundred people. But this is very large for a single black box managed by that many experts, with no mainstream computer scientist-.
For example the AVBP software has about 200 000 lines. Assuming one hour to completely understand 50 statements of code, one would need more than two and a half years to read the code (1600 hours/year, no mails). In a three year french PhD timeframe, you can reasonably assume that a maximum of ten percent of the code can be read, understood, and edited by a single worker. Such a situation is a fertiliser for dangerous code smells: spaghetti code, cut and paste programming, and many more.
Large legacy codes imply that a single person can only work on a small aspect. The key is to efficiently use this tessellation of staff effort on the great ensemble.
How to make the best of this situation?
The challenge of working with legacy code is not limited to Fortran, and plenty of excellent resources already exist. You can start with some vulgarization articles, or investigate further with specialised authors, such as Adam Tornhill.
In the EXCELLERAT CoE, we focused first on reducing the time needed for a new developer to understand the abstract ideas of someone else, coded in Fortran., by promoting an homogeneous coding style via the use of linters. The success of Python PeP-0008 coding standard is a good illustration of the project. Unfortunately, Fortran linters are scarce and often commercial. Moreover, the reader will understand now that large HPC legacy Fortran codes needs the following additional characteristics:
- OpenSource, to be sure what the linter make in my outdated but mandatory fortran66 routine (retro-compatibility prevails!)
- Easy to install and imbed in continuous integration pipelines, to provide a systematic enforcement.
- A customisable and and extendable set of rules because every community comes with its specific preferences.
- The ability to spot clearly the weak parts because a single person cannot do the full work.
- Inclusivity. Fortran did change a lot, from Fortran (19)66 to Fortran 2018, and all versions shall be accepted.
Here is a very partial shortlist of existing fortran linters (Please contact me if you know good entries for this list):
- fortran-linter is light and free, but without customisation yet.
- the linter-gfortran is a plug-in for the Linter of ATOM Integrated Development Editor. While perfect from the ATOM IDE, it is a bit complex to use automatically in a continuous integration pipeline.
- Cleanscapes’s FortranLint is a commercial one.
The well-known Fortran standards are oriented toward compilers, not humans. Concerning coding style, there is no widely adopted standard in the community yet. The Fortran90 best practices is a good starting point. and, both Colorado State University Fortran Coding Style and the Fortran StdLib Style Guide are worth mentioning.
Consequently the EXCELLERAT CoE developed its own very lightweight linter, flinter, with an initial set of rules inspired by the Colorado State Coding Style and the Python PEP-0008. The customisable set of rules should help the comparison of different teams coding styles, and -maybe- converge to a more general set of rules.
What is the added value of checking the coding styles?
The advantages of monitoring the coding style will be illustrated in this last section. Several code bases are checked, and the global figures are reported in the following table:
| Name | version | size (statements) | raw flint score (blind test) |
|---|---|---|---|
| Nek5000 | v19 No Refactoring | 50 008 | -5.73 |
| AVBP sources | 7.7 | 193 257 | 0.53 |
| AVBP tools | 7.7 | 136 387 | 0.93 |
| AVSP sources | 6.1 | 30 636 | -0.56 |
| NTMIX sources | 5.1 | 28 363 | 0.01 |
| NTMIX sources | 3.0 | 31525 | -0.28 |
All these scores are computed with the same coding style. However do remember that this default coding style IS NOT the one enforced by each development team.
As the rules are customizable, it was not possble to use a predetermined score, such as FCRCS ‘Fortran Code Readability/Comprehensibility Scale’ (read more in the 2011 THesis of Mariano Mendez Fortran Refactoring for LegacySystems).
The rating formula therefore is similar to pylint, which also takes into account a variable set of rules:
rate = (struct_nb * 5 + syntax_nb) / stmt_nb * 10
In this formula:
stmt_nbare the number of statements (no blank lines or comments, not continuation lines). This number is therefore smaller than the actual number of lines.syntax_nbare the number of syntax warnings. It can range from a mere space character missing around an operator, to a bareEXITwithout error code (*i.e. a correct end from the Unix point of view, even if this exit comes from a sanity test failing).struct_nbare structural warnings, ranging from too long routines (a single subroutine of 5000k statements is inhumane to maintain.) to to short variable names (try to rename the variabletin a text…).
Like pylint, the maximum score is 10. A rating of 0 or below mean the author were just not aware of this coding style. There is no minimum score, but you can easily reach -100, especially on short routine while taking care of spacings.
Refactoring monitoring
In this first comparison, a CFD direct numerical simulation code has been refactored. In this first adhesion circle scan, the version 3.0 shows many bad-rated (Purple) small routines on the lefthand side.
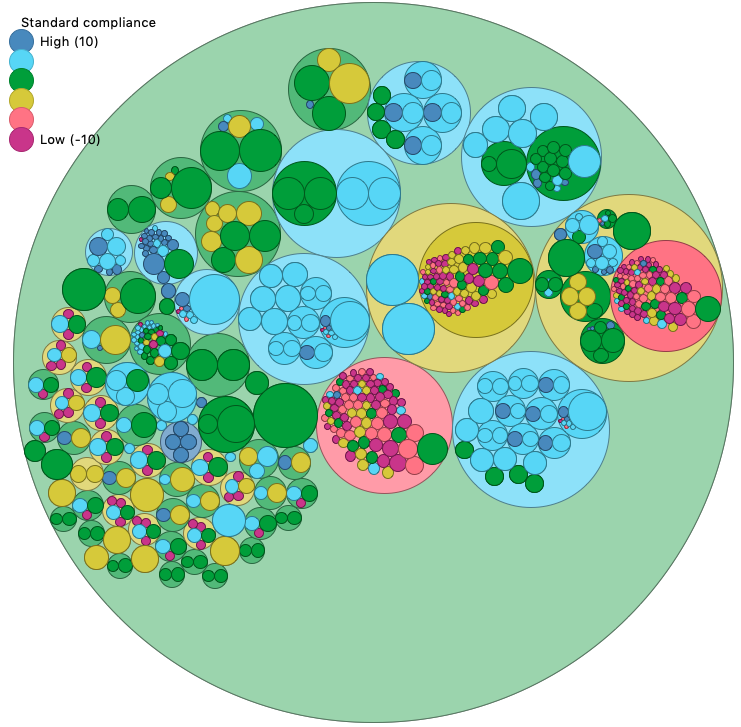
Scan of NTMIX v3, before refactoring (rated -0.28)
On the following refactored version, these badly rated routines vanished. Actually, they were merged into larger routines and cleaned. In case you were wondering, these routines are all named dfdx_* and dfdy_*, meaning the refactoring was done, at least, on the gradient operators.
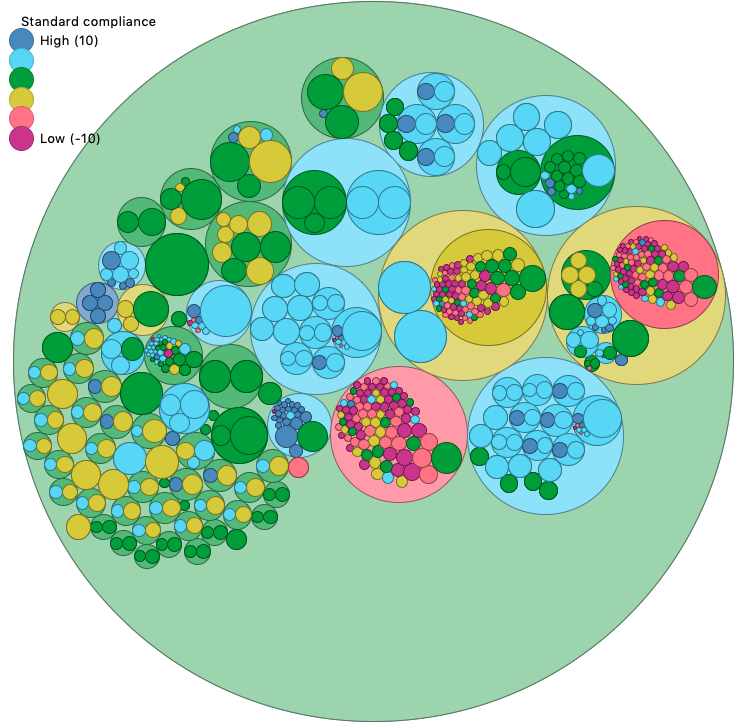
Scan of NTMIX v5, after refactoring (rated 0.01)
This example illustrate the typical task of refactoring, with someone rewriting a batch of selected file.
Two solvers from two teams
In the following we will compare two general purpose academic CFD codes, Nek5000 and AVBP.
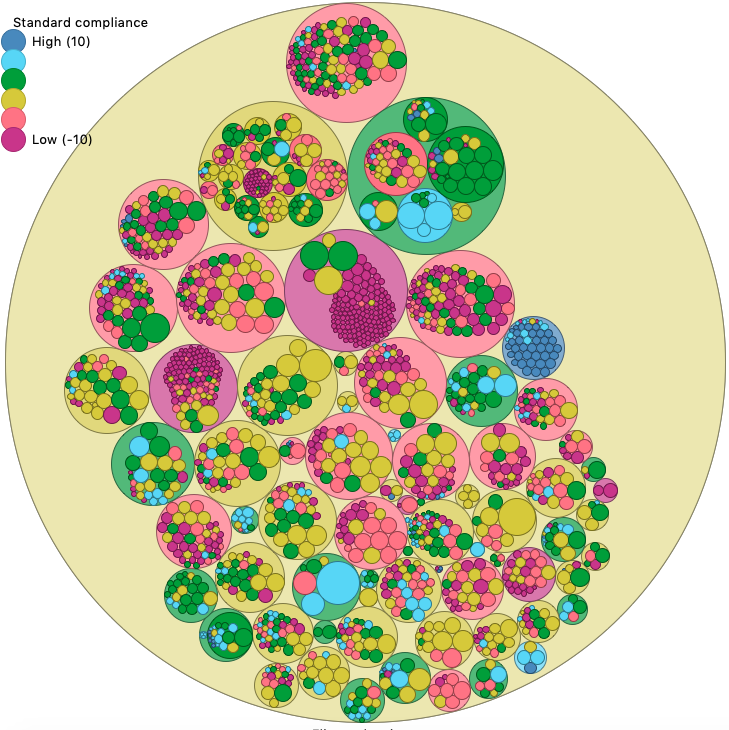
Scan of Nek5000 v19, before refactoring (rated -5.73)
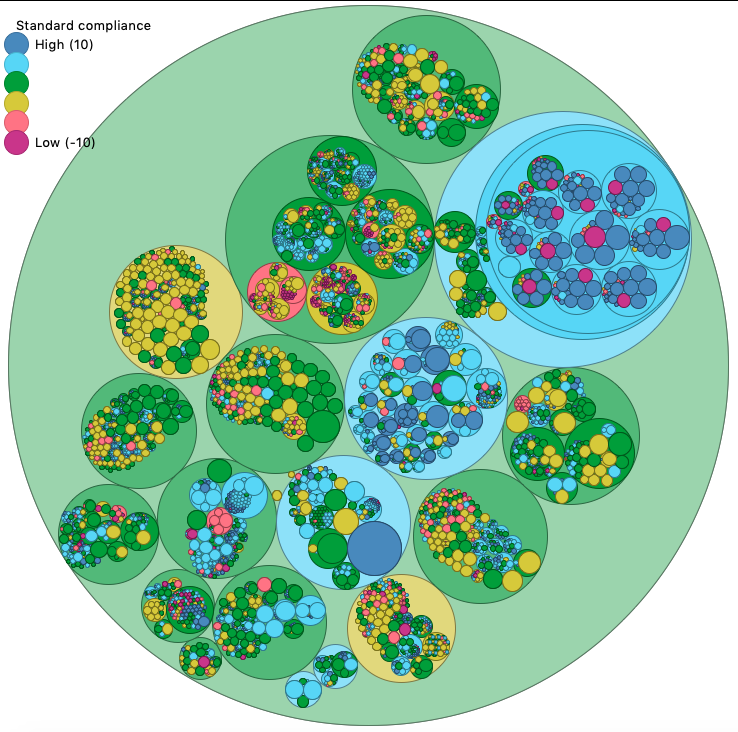
Scan of AVBP V7.7 (rated 0.53)
The two scans show that the default coding style is closer to the one enforced in the AVBP team. A different default style could have given the opposite result. For example, you see AVBP is allowing more nesting in the sources (see the upper blue part, related to analytic chemistry schemes). Nesting sources can be seen as a bad pattern, because it makes the navigation difficult. This trait is not part of the current coding style, and could have decreased the rating of AVBP with respect to Nek5000.
The proper coding style should always be defined by the developers, and never blindly imposed.
Same teams, different solvers
To illustrate how coding styles are team-dependent, we will look at two more projects from Cerfacs.
First, there are the tools used alongside the combustion simulations of AVBP. These tools are independent of each other. This explains the extraordinary variability in size in the first circle. So independent in fact that some lines are duplicated, instead of being shared. You can spot four identical structures on the right part, which are four repetitions, with slight tunings, of the same open-source Chemkin library.
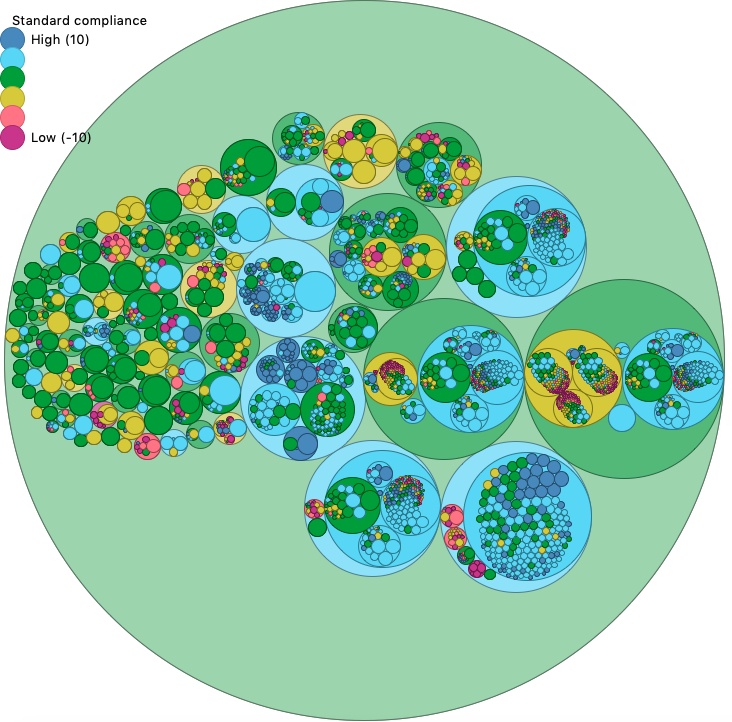
Scan of tools related to AVBP (rating 0.93)
This is followed by AVSP, a Helmholtz solver built on the parallel structure of AVBP. The code is seven times smaller, and under a lower development stress.
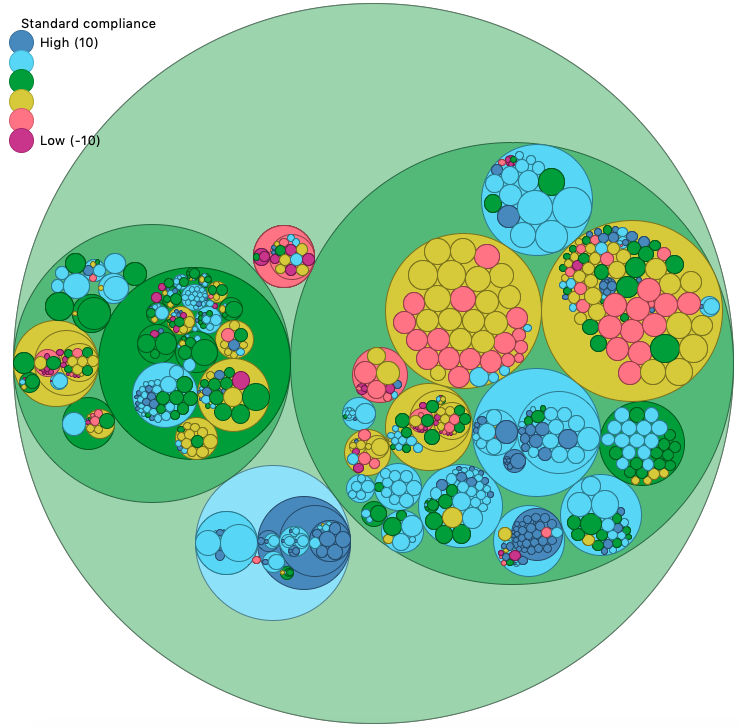
Scan of AVSP, spin of AVBP (rating -0.56)
Surprisingly, four different projects developed by the same team show global rating in the range [-1, 1], while the rating formula allows [-100, 10]. In other words, the “distance” to the standard is globally the same.
Takeaway
We have noted that in the majority of software selected by an HPC Centre of Excellence for engineering applications are large Fortran Legacy codes. We have shown that, in this context, “large” means that the usual single worker can only edit these small parts of the source code.
The EXCELLERAT project, trying to promote the use of HPC by engineers, provided flinter, a tool helping developers to observe and monitor from a maintenance point of view these small parts. The tool compute the adhesion of code parts to a customisable coding style. The examples have illustrated that coding styles are already enforced in the tested situations, and that refactoring already involves coding style improvements.
We stress here that in the flinter score, like in pylint, the syntax warning (spaces, deprecated uses etc…) are far less important , or more readable, that structural warnings (too many variables, indescriptive naming, bloated functions or subroutines). Some fortran compilers like NAG can clean partially clean the syntax errors and move to a more recent code expression. However the structure refactorings must be done manually, and the adhesion circle scans can tell where refactoring matters.
The comparison of these coding styles among EXCELLERAT partners will be the topic of a future communication.
Acknowledgements
This work has been supported by the EXCELLERAT project which has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No 823691.
![]()
Many thanks to Jérôme Lecomte, who kindly provided the community with the nice circlify package which enables the circular packing to be computed, and codemetrics, which gives a lot of insights into the code we wrote.