Tags :
- HPC: High Performance Computing management
- Excellerat: Relative to the task WP7.2 Standardization
Reading time: 6 min
Herding massive flocks of engineering HPC simulations

How mass-production HPC simulations differ from usual ones
High performance Computing (HPC) has uses ranging from fundamental research to industrial design. The European Center of Excellence EXCELLERAT focuses on promoting the use of future HPC resources for engineers. Transferring tools built for academics experts to the day-to-day toolbox of active engineers is the usual technology acceptation challenge, often nicknamed “crossing the chasm”.

Most HPC users are early adopters. They can produce simulations for complex industrial applications, and sometimes “farm” (repeating variation of the same run) around a specific simulation. But conquering the early majority is to move to mass production of successful simulations several years in a row. And from the engineer point of view, a successful simulation implies new constraints:
- The set-up is correct.
- The modeling is correct.
- The job succeeded.
- The output gave insights.
- Steps 1-to-4 can be done in a affordable time.
- The same job can be restarted weeks or years later.
These constraints shift the main objectives. HPC performance can become a second-order concern, when not running the wrong simulation or not loosing a good simulation saves more time and money than a 20% speed improvement. This is why software developers need a specific feedback to focus their efforts.
The following strip, taken from a true story, illustrates the practical problems actors are encountering daily. Behind this story, the simple identification of failed runs in a mass production has proven to be a challenge.

To be more precise, while all HPC users know how much of allocation was spent, there is no systematic report on what was simulated, “how many tries it took, even less on the nature of the failures*.
The CoE EXCELLERAT put effort in this white-paper to show the importance of making this feedback available to the customer.
How feedback can help in “crossing the chasm”
Here are some examples of feedbacks we can use to learn and improve our simulation workflow. The reader can jump to the worked example for more technical details.
As we are talking about high performance computing, this section starts with monitoring the actual performance of a large set of simulations:
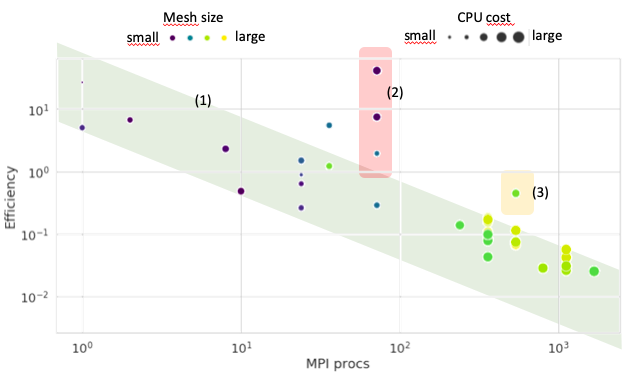
The actual performance of simulations look like a speed-up figure with a lot of outliers. Each point is an actual simulation, and all should collapse to the 1 / cores trend (The lower bound of the green diagonal stripe).
Next is the analysis of crashes. Supposing we add an error code to each simulation log, the distribution of this errors codes shows directly the weak points of the workflow.
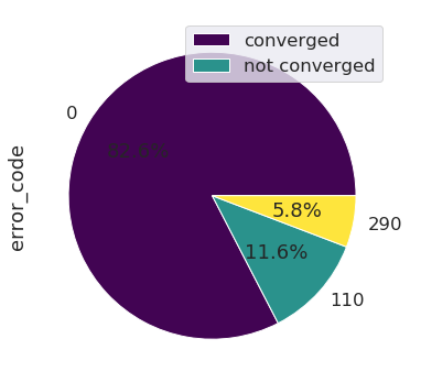
According to this figure, there was in the selected set of simulations a negligible amount of run-time crashes compared to prior-to-run crashes. In other words, some manpower is lost in trial-and-error setup corrections ; an improvement of the user-experience is needed.
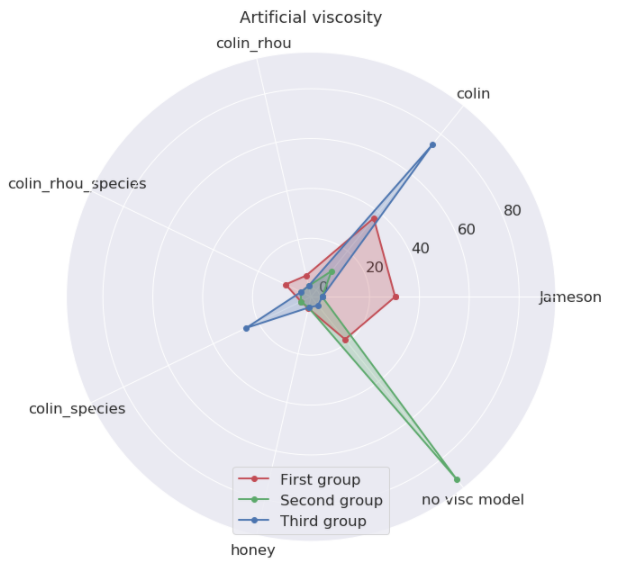
We can push further the investigation by trying to figure out if there were distinct families of simulation on the batch. This can be done with a machine-learning technique , the principal component analysis (PCA).
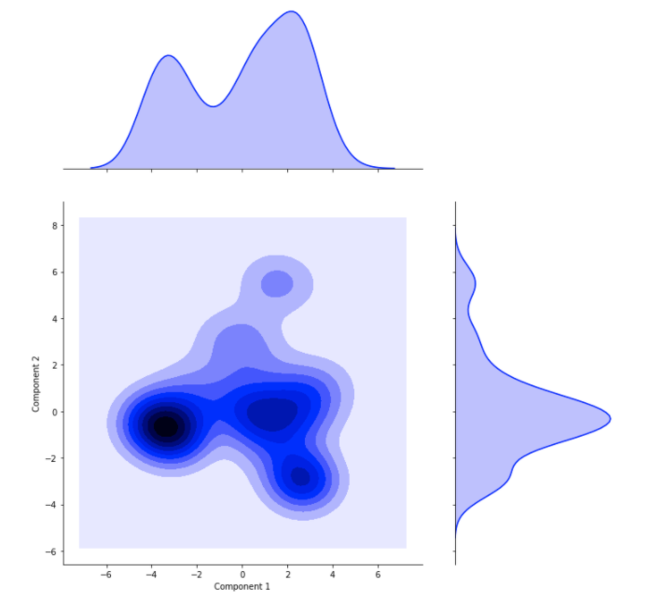
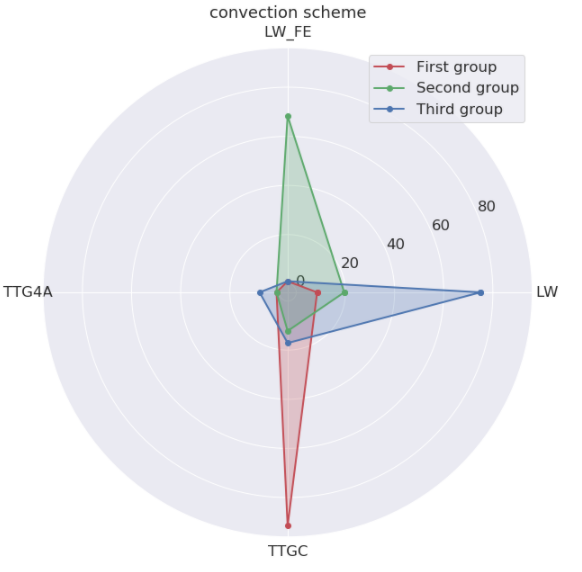
Once the families are separated, we can find their unique traits. In the present case, the numerical approach really changed across the groups.
Takeaway
This white-paper underline the need of a proper feedback to code developer when the simulation workflow must scale up. This feedback can focus on performances, crashes, users habits or any other metric. Unfortunately there is no systematic method available yet.
In short, your organization can envision to add a feedback process on your simulation workflow if:
- HPC costs are not negligible.
- The production is hard to track by a single worker (>1000 jobs per year).
- HPC simulation are part of your design process.
- The usage spans over years.
However, there are still many situations where it would be overkill:
- HPC tools in the demonstration stage.
- The volume of simulation is still manually manageable.
- HPC tool used in a break-trough action.
- This is a one-year journey.
In this worked example, you will see how to create a data-mining tool based upon the existing files (assuming you use it before data is erased…).
Acknowledgements
This work has been supported by the EXCELLERAT project which has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No 823691.
![]()
The authors wish to thank M. Nicolas Monnier, head of CERFACS Computer Support Group for his cooperation and discussions, Corentin Lapeyre, data-science expert, who created our first “all-queries MongoDb crawler”, and Tamon Nakano, Computer science and data-science engineer who followed-up and created the crawler used to build the database behind these figures. (Many thanks in advance to the multiple proof-readers from the EXCELLERAT initiative, of course)