
🎓Markus HOLZER thesis defense
Friday 29 November 2024From 14h30 at 16h30
Phd Thesis FAU Allemagne
Code generation in a lattice Boltzmann framework for exascale computing
Ecole doctorale 475 Mathématiques, Informatique et Télécommunications de Toulouse (EDMITT)
https://fau.zoom-x.de/j/97059928526?pwd=L2hmVHJoSjg5SHd4YiswOUV2OFZUdz09
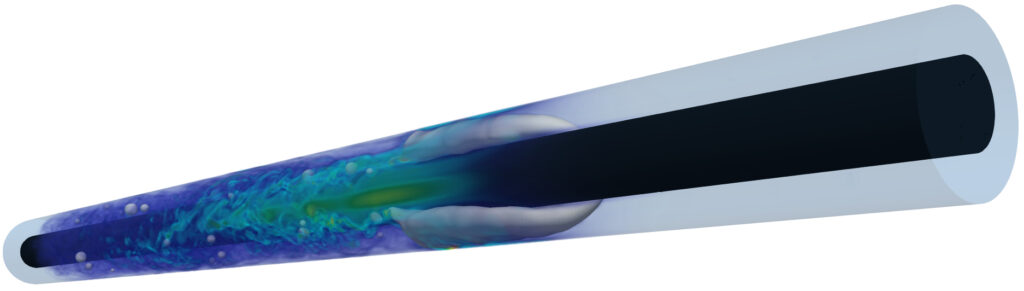
Exascale supercomputers are computing systems capable of performing 1e18 FLOPS. The supercomputer named Frontier first broke this barrier of one exaFLOPS and officially initiated the era of exascale computing in 2022. The immense scale of systems like this imposes significant challenges in developing codes that can fully exploit this computing power. Furthermore, the increasingly heterogeneous hardware employed by today’s leading supercomputers adds another layer of complexity. In the field of computational fluid dynamics, it is therefore crucial to carefully consider every aspect of a numerical simulation, starting with the design and selection of algorithms suited to such environments. For example, algorithms like the lattice Boltzmann method are explicitly designed with massive parallelism in mind, making them a notable alternative to other more established methods. Nevertheless, a highly efficient implementation of this algorithm must be tailored to the respective hardware for optimal usage of resources.
To address these challenges, this thesis explores the use of code generation through an embedded domain-specific language. Code generation enables us to target specific hardware architectures and apply precise optimisations that leverage domain-specific knowledge. In this research, we extend and redesign the Python package lbmpy to support state-of-the-art variants of the lattice Boltzmann method. lbmpy represents the lattice Boltzmann method symbolically using a computer algebra system, allowing the automatic derivation of discretised equations based on user-defined specifications. To obtain equations with a minimal amount of floating-point operations we fundamentally enhance the simplification capabilities of lbmpy in this work. The discretised equations derived by lbmpy are provided to the Python package pystencils, which generates highly optimised architecture-specific compute kernels in a lower-level language from these. We expand the range of supported hardware platforms and overhaul crucial aspects of the code generation process, such as the typing system, to improve performance and maintainability.
A sophisticated integration of these compute kernels into the massively parallel multiphysics framework waLBerla is also developed, with an in-depth discussion of the key implementation components. One of the most significant advancements in this integration is the generation of highly specialised interpolation kernels. These kernels are essential for transferring information between cells of differing resolutions within the simulation domain, ensuring the accuracy and consistency of the data across varying grid sizes. This development has enabled us to perform the largest simulation run to date using the lattice Boltzmann method on a nonuniform domain, utilising more than 4000 AMD MI250X graphics processing
units. The ability to efficiently manage such a vast and heterogeneous computational environment underscores the effectiveness of our approach in scaling complex simulations on next-generation hardware platforms.
We verify and validate our approach by simulating turbulent single-phase flow around a sphere using a nonuniform mesh configuration on graphics processing units, successfully reproducing the drag crisis—a complex phenomenon that occurs at Reynolds numbers above 200 000. Additionally, we demonstrate the capabilities of our method through slug flow simulations, offering new insights into the behaviour of Taylor bubbles in complex annular pipe configurations. Finally, we analyse the trajectories of droplets under the influence of a laser heat source in three-dimensional thermocapillary flows. To evaluate the performance of our approach, we present results from all these scenarios on the latest CPU and GPGPU hardware. We provide single-node performance data and offer valuable insights by contextualising the measured results with appropriate performance models. Lastly, we examine the scalability of our developments by presenting both weak and strong scaling results on several of the world’s leading supercomputers.
JURY
| Jonas LATT | Université de Genève | Referee |
| Christian HOLM | Université de Stuttgart | Referee |
| Ulrich RÜDE | FAU / CERFACS | Referee / Thesis supervisor |
| Jens HARTING | FZ-Jülich | Examiner |
| Tobias GÜNTER | FAU | President of the Jury |
| Eric CLIMENT | IMFT | Examiner |
| Gabriel STAFFELBACH | ONERA | Co-supervisor |
| Catherine LAMBERT | CERFACS | Thesis supervisor |
No content defined in the sidebar.
